Descripción general
La Base de conocimiento utiliza RAG (Generación Aumentada por Recuperación) para dar a su agente acceso al contenido de su negocio. Los documentos se dividen en segmentos, se convierten en embeddings vectoriales y se almacenan para la búsqueda semántica. Navegue a la pestaña Base de conocimiento en el panel del agente. Aquí usted elige qué datos utilizará el agente para sus respuestas.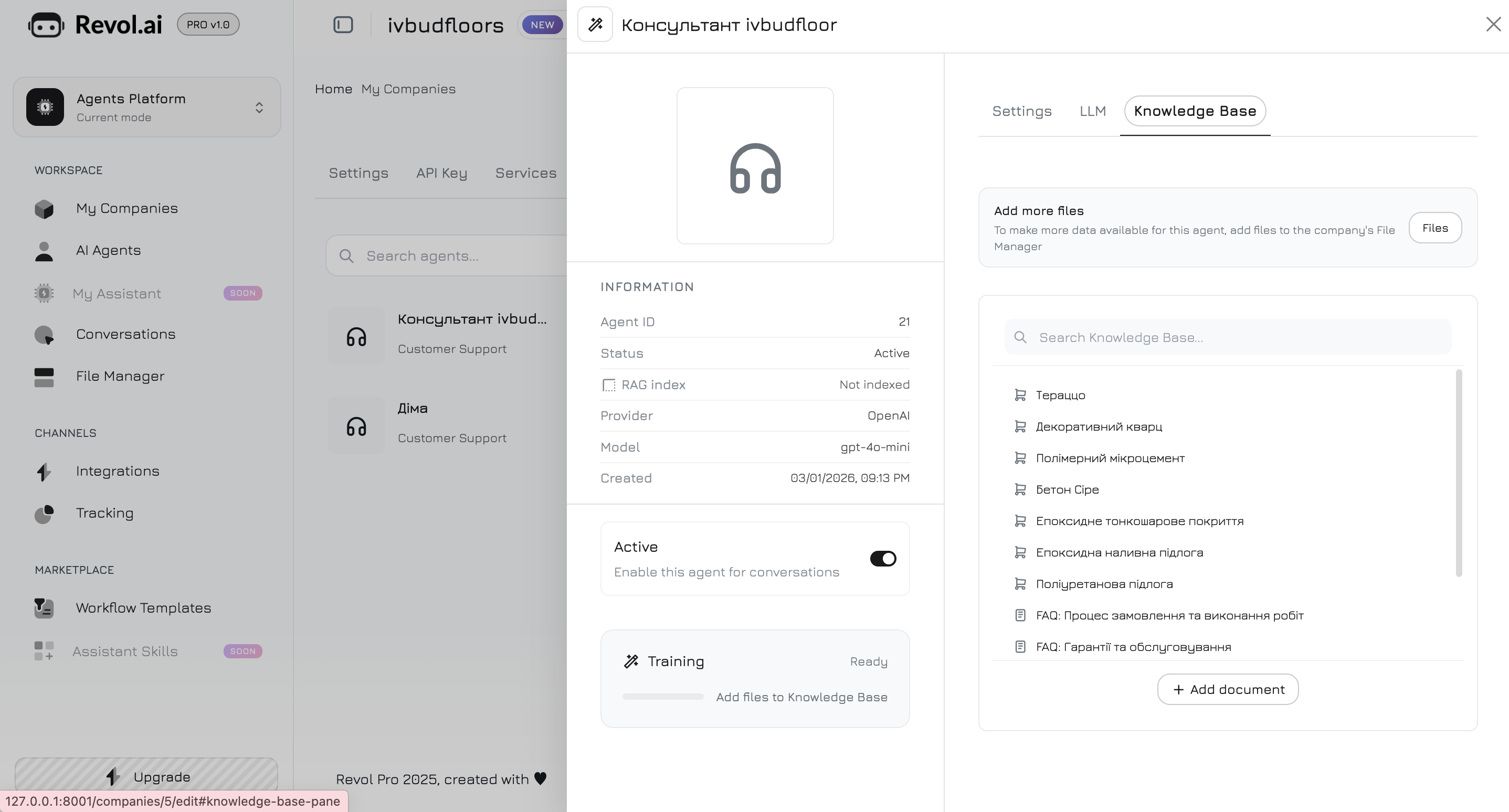
Agregar contenido
Documentos
Suba archivos en formatos compatibles:- DOCX
- TXT
URLs
Proporcione URLs de páginas web. Revol extraerá el contenido y lo agregará a la base de conocimiento.Texto
Agregue contenido directamente como bloques de texto.Cómo funciona RAG
Embedding
Cada segmento se convierte en un embedding vectorial utilizando el modelo de embedding seleccionado.
Recuperación
Cuando un usuario hace una pregunta, se recuperan los segmentos más similares utilizando similitud del coseno.
Configuración de RAG
Abra la configuración de RAG a través del icono de engranaje (⚙) en el panel de almacenamiento de la base de conocimientos. Todas las configuraciones son por empresa y se guardan automáticamente.Modelo de embedding
Elija qué modelo convierte su texto en embeddings vectoriales:| Modelo | Proveedor | Dimensiones | Precio | Ideal para |
|---|---|---|---|---|
| text-embedding-3-small | OpenAI | 1536 | $0.02/1M tokens | Uso general, contenido en inglés |
| text-embedding-3-large | OpenAI | 1536 | $0.13/1M tokens | Mayor precisión, contenido en inglés |
| BGE-M3 | DeepInfra | 1024 | $0.01/1M tokens | Contenido multilingüe (100+ idiomas) |
Límite de chunks
Cuántos fragmentos de texto se devuelven por búsqueda RAG (1–20). Predeterminado: 5. Valores más altos proporcionan más contexto al LLM pero aumentan el uso de tokens.Límite de caracteres
Máximo de caracteres por fragmento al dividir documentos (500–10.000). Predeterminado: 1.500. Fragmentos más pequeños dan una recuperación más precisa. Más grandes preservan más contexto por resultado.Superposición de chunks
Superposición entre fragmentos consecutivos (0–40%). Predeterminado: 15%. La superposición asegura que el contexto importante en los límites de los fragmentos no se pierda. Mayor superposición crea más chunks y usa más almacenamiento.Umbral de similitud
Puntuación mínima de similitud coseno para incluir un resultado (0,1–1,0). Predeterminado: 0,35. Valores más bajos devuelven más resultados (mejor recall). Valores más altos devuelven solo resultados altamente relevantes (mejor precisión). Para contenido multilingüe, use umbrales más bajos (0,3–0,4).Límites de almacenamiento
| Plan | Documentos de conocimiento | Tokens de embedding |
|---|---|---|
| Gratuito | 10 | 100,000 |
| Premium | 100 | 1,000,000 |
| Profesional | 1,000 | 5,000,000 |
Generar base de conocimiento con Claude Code
Si tiene documentación del proyecto (páginas web, portal de documentación, archivos README, wiki) y desea convertirla en una base de conocimiento estructurada para su agente de IA de Revol, puede usar Claude Code para analizar la documentación y generar archivos TXT listos para subir.Prompt para generación de base de conocimiento
Prompt para generación de base de conocimiento