Panel główny
Przejdź do Billing → Overview, aby otworzyć panel analityki zużycia — pojedynczą stronę zapewniającą pełny wgląd w zużycie zasobów, limity platformy oraz szczegółowy dziennik każdego zdarzenia podlegającego rozliczeniu.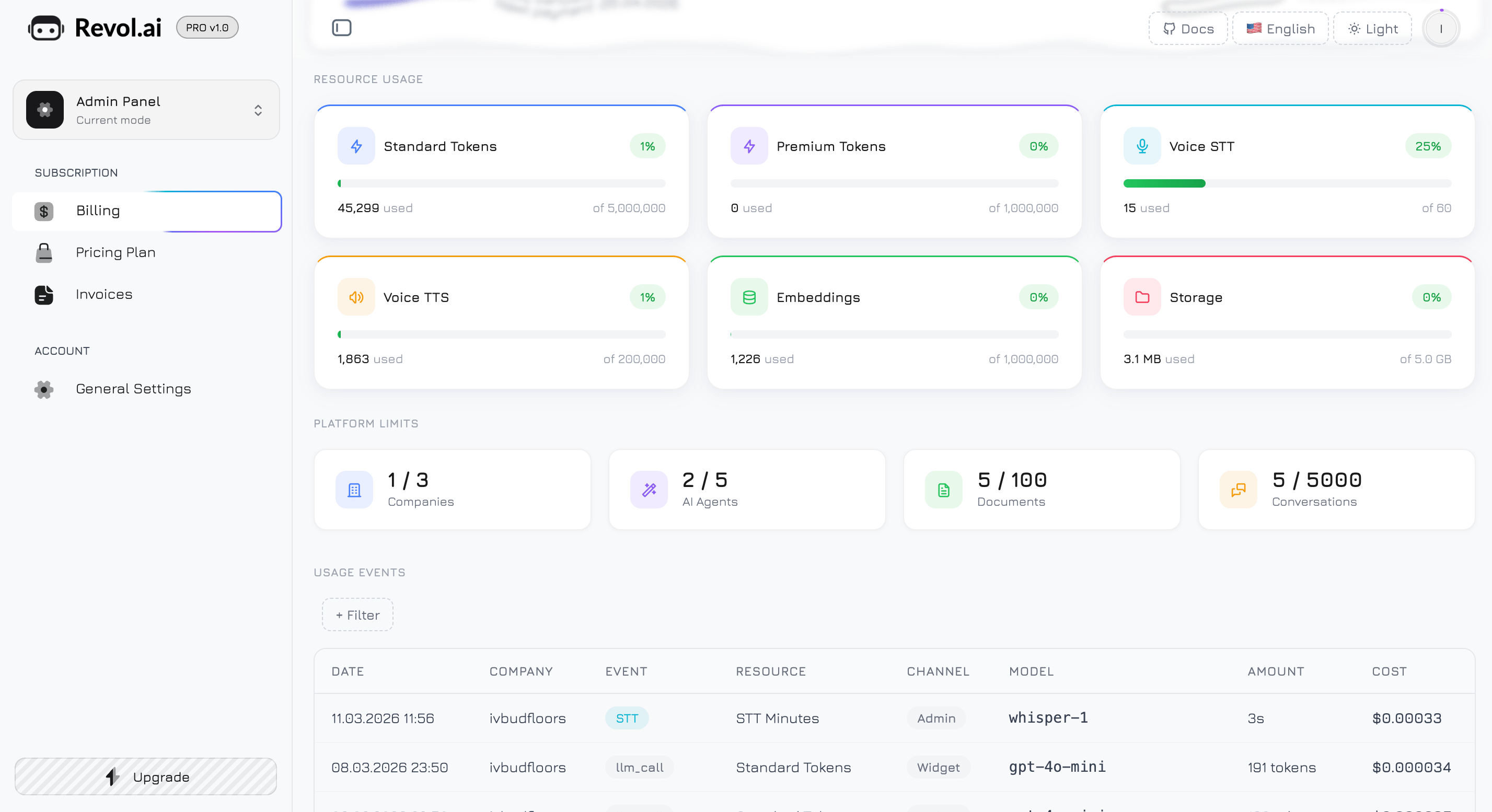
Podsumowanie planu
Na górze strony wyświetla się karta z aktualnymi szczegółami subskrypcji. Lewa strona:- Gradientowa plakietka z nazwą planu (Free, Premium lub Professional) z ikoną korony
- W przypadku płatnego planu — cena miesięczna (np. $29 /mies.) oraz data następnej płatności (np. „Następna płatność: 15.04.2026”)
- W przypadku planu Free — zachęta do aktualizacji
- Przycisk Manage — otwiera modal zarządzania subskrypcją (tylko plany płatne). Zobacz Zarządzanie subskrypcją
- Przycisk Upgrade Plan / Change Plan — prowadzi do strony Cennik
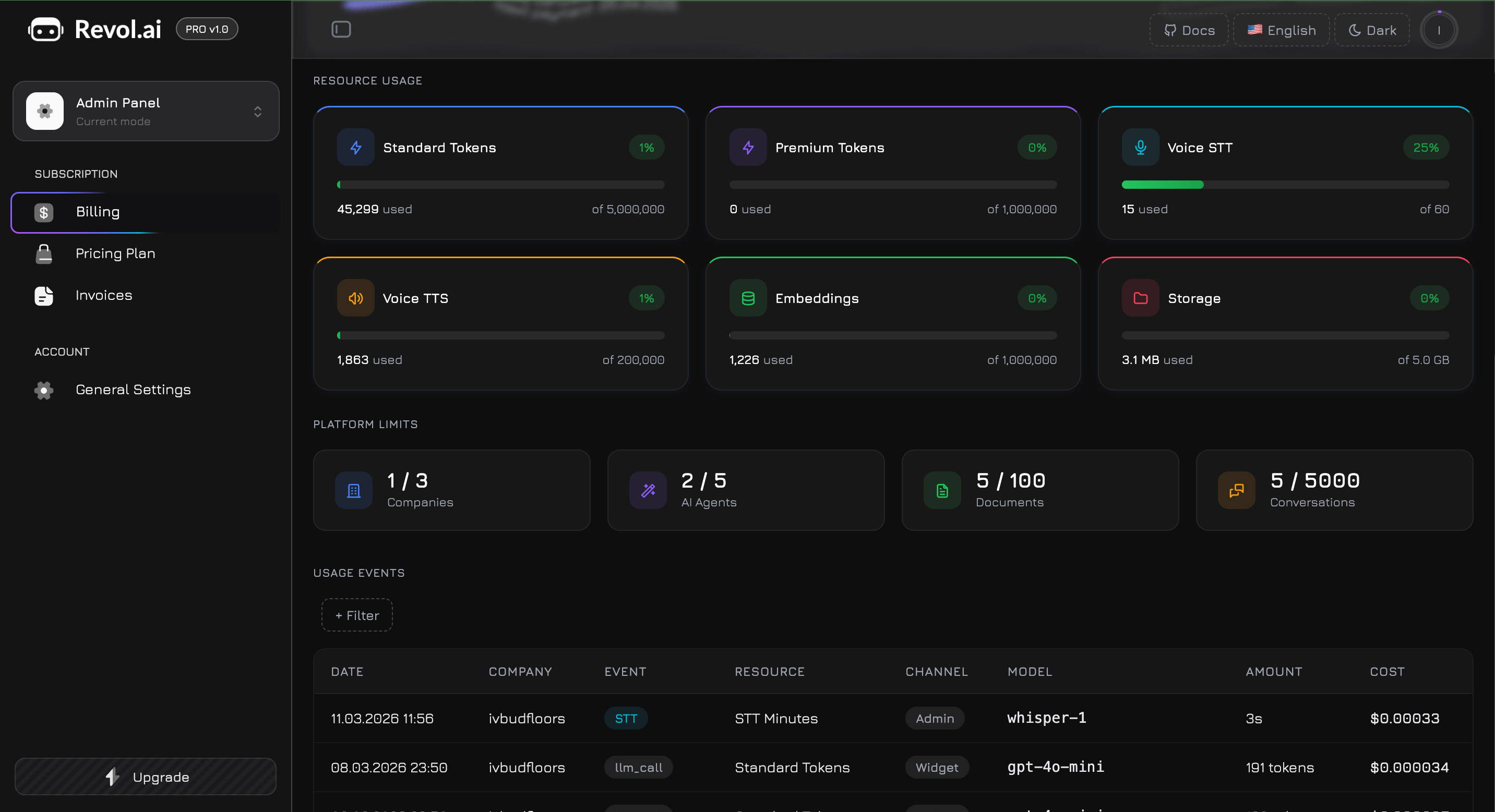
Zużycie zasobów
Sześć kart z paskami postępu ułożonych w siatkę 3-kolumnową (2 kolumny na tablecie, 1 na telefonie). Każda karta śledzi jeden zasób podlegający rozliczeniu w czasie rzeczywistym.| # | Zasób | Ikona | Co mierzy |
|---|---|---|---|
| 1 | Tokeny standardowe | Błyskawica (niebieski) | Tokeny zużyte przez modele standardowe — GPT-4o Mini, Claude 3.5 Haiku, Gemini 2.0 Flash, Llama 3.1 8B |
| 2 | Tokeny premium | Błyskawica (fioletowy) | Tokeny zużyte przez modele premium — GPT-4o, Claude 3.5 Sonnet, Gemini 2.5 Pro, Llama 3.3 70B |
| 3 | Głos STT | Mikrofon (cyjan) | Czas transkrypcji mowy na tekst w minutach |
| 4 | Głos TTS | Głośnik (bursztyn) | Synteza tekstu na mowę w znakach |
| 5 | Embeddingi | Baza danych (zielony) | Tokeny użyte do trenowania bazy wiedzy (chunking + generowanie wektorów) |
| 6 | Pamięć masowa | Folder (różowy) | Łączna pamięć plików we wszystkich firmach |
- Wiersz nagłówka — ikona zasobu i etykieta po lewej, plakietka procentowa po prawej
- Pasek postępu — pasek 8px pokazujący aktualne zużycie jako wypełniony gradient
- Wiersz wartości — „N użyto” po lewej, „z N” (limit planu) po prawej
Progi kolorystyczne
Plakietka procentowa i pasek postępu zmieniają kolor w zależności od poziomu zużycia:| Poziom zużycia | Kolor | Znaczenie |
|---|---|---|
| Poniżej 80% | Zielony | Normalny — masz duży zapas |
| 80% – 89% | Bursztynowy | Ostrzeżenie — rozważ aktualizację lub zakup pakietu |
| 90% i więcej | Czerwony | Krytyczny — zbliżasz się do limitu, żądania mogą wkrótce zostać zablokowane |
Limity platformy
Cztery karty liczników poniżej mierników zasobów, ułożone w siatkę 4-kolumnową (2 na tablecie, 1 na telefonie). Pokazują, ile zasobów platformy utworzono w porównaniu z maksimum planu:| Ikona | Licznik | Przykład |
|---|---|---|
| Budynek (niebieski) | Firmy | 2 / 3 |
| Różdżka (fioletowy) | Agenci AI | 4 / 5 |
| Dokument (zielony) | Dokumenty wiedzy | 45 / 100 |
| Wiadomości (bursztyn) | Konwersacje | 1 200 / 5 000 |
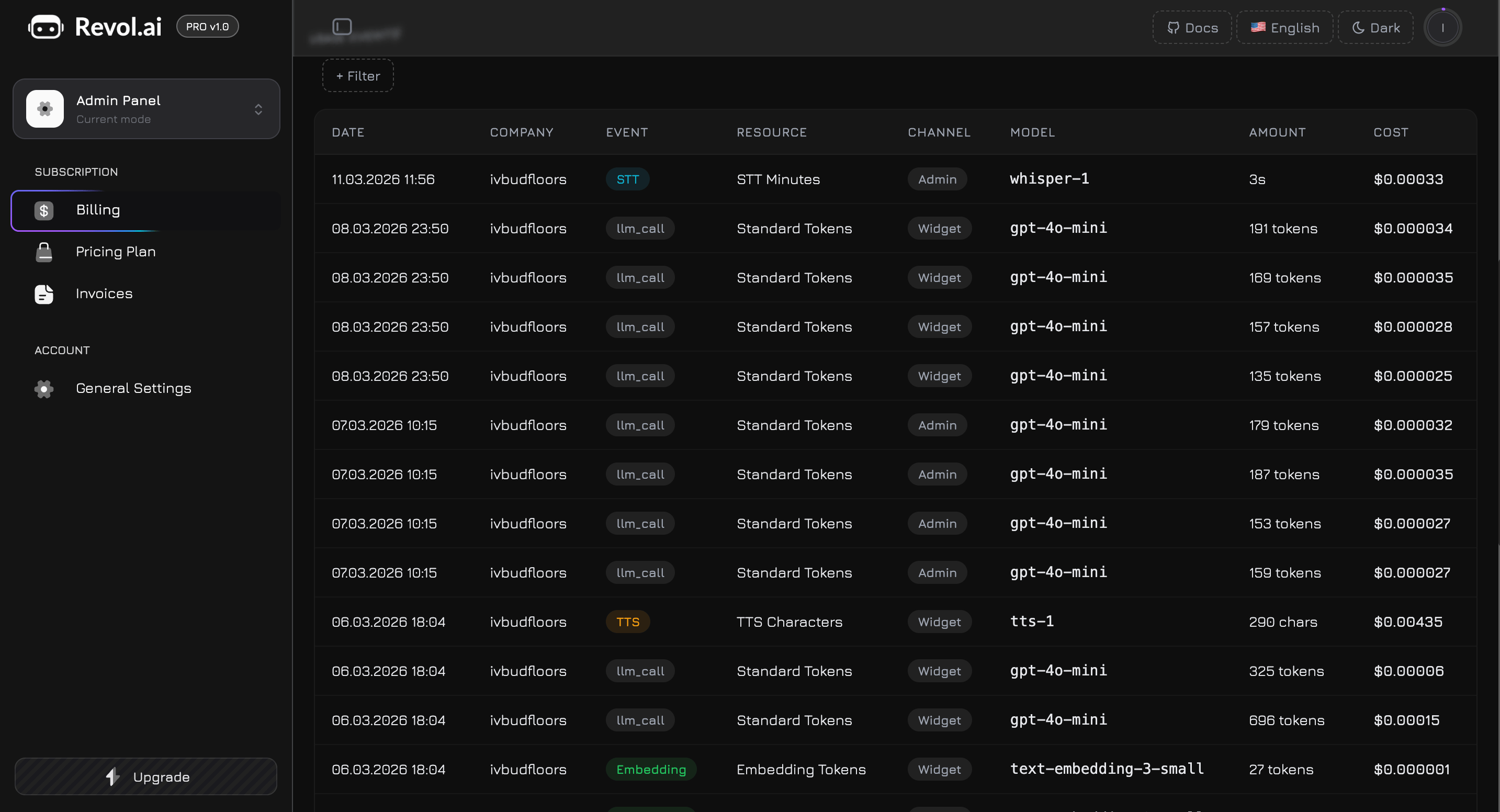
Zdarzenia zużycia
Dolna sekcja zawiera szczegółową, filtrowalną tabelę rejestrującą każdą akcję podlegającą rozliczeniu we wszystkich firmach. To Twoja ścieżka audytu pozwalająca dokładnie zrozumieć, co zużyło Twój limit.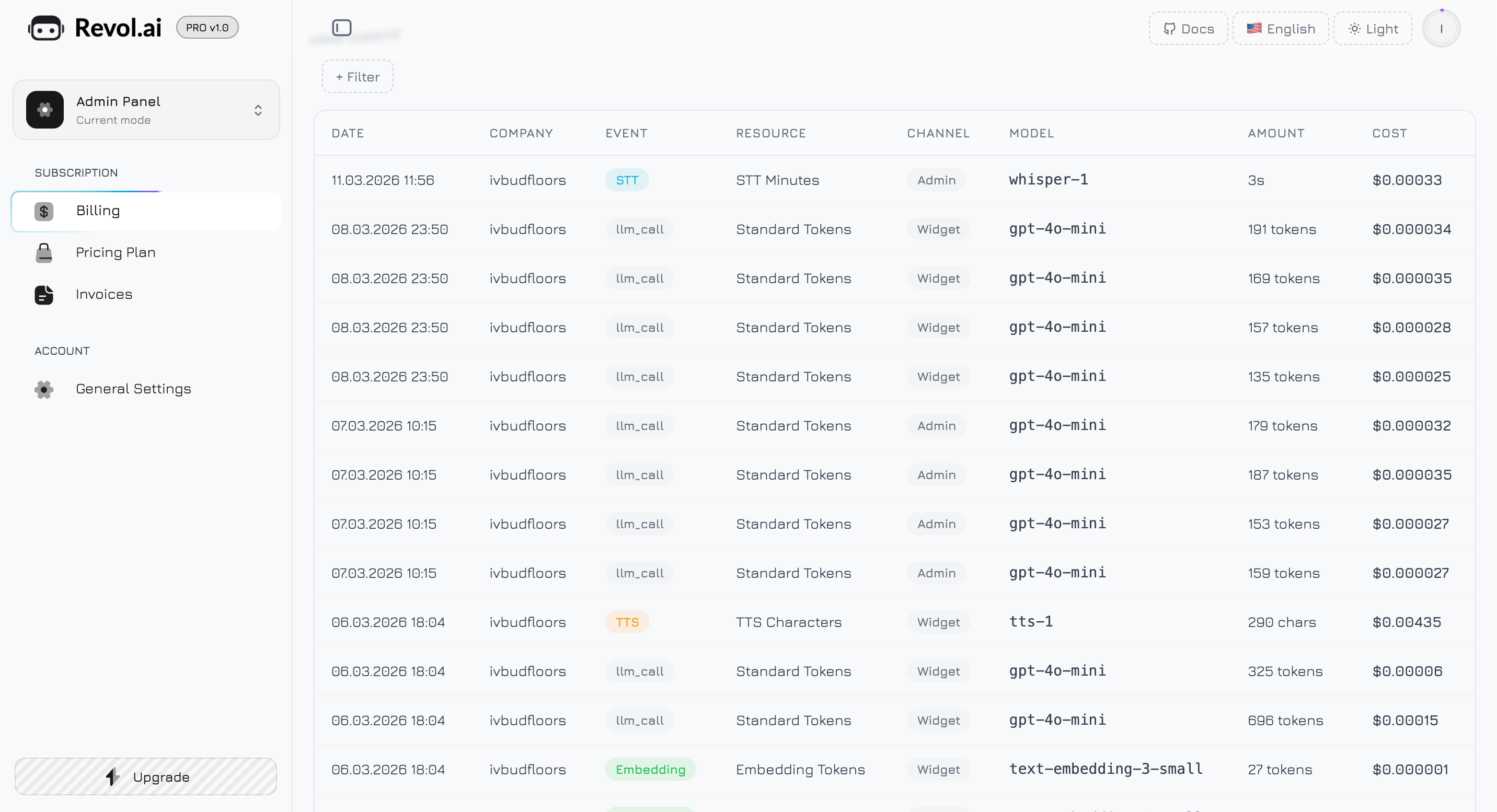
Filtrowanie
Kliknij przycisk + Filter, aby dodać filtry. Dostępnych jest sześć typów filtrów:| Filtr | Typ | Opcje |
|---|---|---|
| Data od | Wybór daty | Kalendarz — wybierz datę początkową |
| Data do | Wybór daty | Kalendarz — wybierz datę końcową |
| Firma | Lista rozwijana | Wszystkie Twoje firmy według nazwy |
| Typ zdarzenia | Lista rozwijana | Chat, Workflow, STT, TTS, Embedding, Storage |
| Zasób | Lista rozwijana | Standard Tokens, Premium Tokens, STT Minutes, TTS Characters, Embedding Tokens, Storage |
| Kanał | Lista rozwijana | Admin, Widget, System |
Kolumny tabeli
Każdy wiersz tabeli reprezentuje pojedyncze zdarzenie podlegające rozliczeniu z ośmioma kolumnami:| Kolumna | Opis | Format |
|---|---|---|
| Data | Kiedy zdarzenie wystąpiło | DD.MM.RRRR GG:mm |
| Firma | Która firma wywołała zdarzenie | Nazwa firmy lub — dla zdarzeń systemowych |
| Zdarzenie | Typ akcji podlegającej rozliczeniu | Kolorowa plakietka (patrz niżej) |
| Zasób | Który limit zasobu został zużyty | Zwykła etykieta tekstowa |
| Kanał | Skąd pochodziła interakcja | Szara plakietka (Admin, Widget, System) lub — |
| Model | Który model LLM został użyty | Czcionka monospace (np. gpt-4o-mini) lub — dla zdarzeń nie-LLM |
| Ilość | Zużyta ilość | Inteligentne formatowanie (patrz niżej) |
| Koszt | Szacunkowy koszt w USD | Pogrubiony, tabelaryczne cyfry (patrz niżej) |
Plakietki typów zdarzeń
Każdy typ zdarzenia ma odrębną kolorową plakietkę dla szybkiego wizualnego rozpoznania:| Typ zdarzenia | Kolor plakietki | Opis |
|---|---|---|
| Chat | Niebieski | Wnioskowanie LLM z rozmowy czatowej |
| Workflow | Fioletowy | Wnioskowanie LLM z wykonania węzła workflow |
| STT | Cyjan | Transkrypcja mowy na tekst |
| TTS | Bursztynowy | Synteza tekstu na mowę |
| Embedding | Zielony | Trenowanie bazy wiedzy (generowanie wektorów) |
| Storage | Różowy | Przesyłanie pliku lub operacja na pamięci masowej |
Formatowanie ilości
Kolumna Ilość dostosowuje format wyświetlania w zależności od typu zasobu:| Zasób | Format | Przykład |
|---|---|---|
| Tokeny (Standard, Premium, Embedding) | Liczba z separatorami + „tokens” | 4,521 tokens |
| Minuty STT | Minuty i sekundy | 2m 34s |
| Znaki TTS | Liczba z separatorami + „chars” | 1,250 chars |
| Pamięć masowa | MB lub KB | 3.2 MB, 450 KB |
Formatowanie kosztów
Kolumna Koszt pokazuje szacunkowy koszt w USD z precyzją dostosowaną do wartości:- **1.25`)
- **Poniżej 0.00042`)
- Zero lub nie dotyczy — wyświetlane jako
—
Paginacja
Tabela ładuje 25 zdarzeń na stronę i używa asynchronicznej paginacji. Dolny pasek pokazuje:- „Showing X–Y of Z” — aktualny zakres i łączna liczba
- Przyciski stron — pierwsza strona, ostatnia strona oraz okno ±2 stron wokół aktualnej, z wielokropkiem (
…) dla przerw
Jak działają tokeny
Każda interakcja z AI składa się z dwóch części:- Tokeny wejściowe — Twoja wiadomość + prompt systemowy + kontekst bazy wiedzy (fragmenty RAG) + historia konwersacji + opisy narzędzi
- Tokeny wyjściowe — odpowiedź agenta
- Długości promptu systemowego — dłuższe prompty zużywają więcej tokenów wejściowych na wiadomość
- Kontekstu bazy wiedzy — więcej pobranych fragmentów RAG = więcej tokenów wejściowych. Kontroluj to przez RAG Settings → Chunk Limit
- Historii konwersacji — dłuższe konwersacje kumulują kontekst z poprzednich wiadomości
- Długości odpowiedzi — kontrolowana suwakiem Response Length w ustawieniach osobowości agenta
- Wywołań narzędzi — każda runda wywołania narzędzia dodaje tokeny wejściowe (opisy narzędzi) i wyjściowe (argumenty + wyniki narzędzia)
Typy tokenów
| Typ tokena | Modele | Profil kosztów |
|---|---|---|
| Standardowy | GPT-4o Mini, Claude 3.5 Haiku, Gemini 2.0 Flash, Llama 3.1 8B | Niższy koszt, szybsze odpowiedzi |
| Premium | GPT-4o, Claude 3.5 Sonnet, Gemini 2.5 Pro, Llama 3.3 70B | Wyższy koszt, lepsza jakość |
| Embedding | text-embedding-ada-002 | Używany tylko podczas trenowania bazy wiedzy |
Zużycie głosu
Interakcje głosowe zużywają dwa oddzielne zasoby:- STT (Speech-to-Text) — mierzone w minutach. Każda wiadomość głosowa jest transkrybowana, a czas trwania (zaokrąglony w górę do najbliższej minuty) jest odejmowany od limitu.
- TTS (Text-to-Speech) — mierzone w znakach. Tekstowa odpowiedź agenta jest syntetyzowana do audio, a liczba znaków jest odejmowana.
Zużycie pamięci masowej
Pamięć masowa jest zużywana podczas przesyłania plików do Menedżera plików:- Dokumenty — PDF, Word, Excel, TXT
- Zdjęcia — JPG, PNG
- Wideo — MP4, WebM, MOV
- Nagrania audio — pliki audio z konwersacji
Powiadomienia o limitach
Revol monitoruje Twoje zużycie i wysyła alerty przed osiągnięciem limitów:| Próg | Poziom | Powiadomienie |
|---|---|---|
| 80% | Ostrzeżenie | E-mail + baner w aplikacji: „Wykorzystano 80% zasobu [zasób]. Rozważ aktualizację lub zakup pakietu.” |
| 90% | Krytyczny | E-mail + baner w aplikacji: „Wykorzystano 90% zasobu [zasób]. Żądania zostaną zablokowane przy 100%.” |
Co się dzieje przy osiągnięciu limitu
| Zasób | Zachowanie |
|---|---|
| Tokeny standardowe / premium | Agent przestaje odpowiadać do następnego cyklu rozliczeniowego lub do zakupu pakietu |
| Pamięć masowa | Nie można przesyłać nowych plików do Menedżera plików |
| Głos (STT/TTS) | Funkcje głosowe są wyłączone, czat tekstowy nadal działa |
| Konwersacje | Nowe konwersacje są blokowane, istniejące kontynuują |
| Dokumenty wiedzy | Nie można dodawać nowych dokumentów do baz wiedzy agentów |
Okres rozliczeniowy
- Plan Free — dzienny okres rozliczeniowy. Zużycie tokenów resetuje się codziennie o północy UTC.
- Plany płatne — miesięczny okres rozliczeniowy. Zużycie resetuje się w rocznicę daty subskrypcji (np. jeśli subskrypcja rozpoczęła się 15 marca, następny reset jest 15 kwietnia).