Was sind KI-Agenten?
KI-Agenten in Revol sind intelligente Assistenten, die Kundeninteraktionen über mehrere Kanäle hinweg verarbeiten — Ihr Website-Widget, Telefonanrufe, Telegram, WhatsApp und Instagram. Jeder Agent hat seine eigene Persönlichkeit, Wissensdatenbank, Gesprächs-Workflow und eine Reihe von Werkzeugen.Betriebsmodi
Agenten können je nach Ihren geschäftlichen Anforderungen in drei Modi betrieben werden:| Modus | Wer kommuniziert | Rolle des Agenten |
|---|---|---|
| Aktiv | KI-Agent | Der Agent übernimmt die gesamte Kundenkommunikation — beantwortet Nachrichten, ruft Werkzeuge auf, folgt dem Workflow und löst Anfragen eigenständig |
| Passiv | Ihr Team | Ihr Team übernimmt die gesamte Kundenkommunikation. Der Agent überwacht jede Konversation im Hintergrund — prüft die Einhaltung von Kommunikationsstandards, verfolgt Qualitätskennzahlen und liefert Analysen, ohne jemals den Kunden zu antworten |
| Hybrid | Beide | Die KI übernimmt Routineinteraktionen (FAQ, Produktanfragen, Terminplanung), während Ihr Team komplexe oder sensible Fälle bearbeitet. Der Agent analysiert kontinuierlich alle Konversationen, unabhängig davon, wer antwortet |
Einen Agenten erstellen
Klicken Sie auf Agent erstellen, um einen 2-Schritte-Assistenten zu starten: Schritt 1 — Geben Sie den Agentennamen ein (mindestens 3 Zeichen) und optional eine erste Nachricht (Begrüßungstext). Schritt 2 — Wählen Sie einen Anwendungsfall: Kundensupport, Outbound-Vertrieb, Lead-Qualifizierung, Anrufbeantworter, Terminbuchung, Kundenaufnahme, Serviceempfehlungen, Terminplanung, Rechnungsanfragen, Projektaktualisierungen, Ressourcenbibliothek, Lernen & Entwicklung oder Sonstiges. Dies ist rein visuell — der gewählte Anwendungsfall beeinflusst weder das Verhalten noch die Konfiguration des Agenten. Nach der Erstellung startet der Agent im Status Entwurf mit einem bereits erstellten Standard-Workflow.Agentenstatus
| Status | Verhalten |
|---|---|
| Entwurf | Nicht aktiv. Verwenden Sie ihn während der Konfiguration. |
| Aktiv | Live, antwortet auf Nachrichten. Nur ein Agent pro Unternehmen kann aktiv sein — die Aktivierung eines Agenten deaktiviert alle anderen. |
| Inaktiv | Pausiert. Behält alle Konfigurationen bei. |
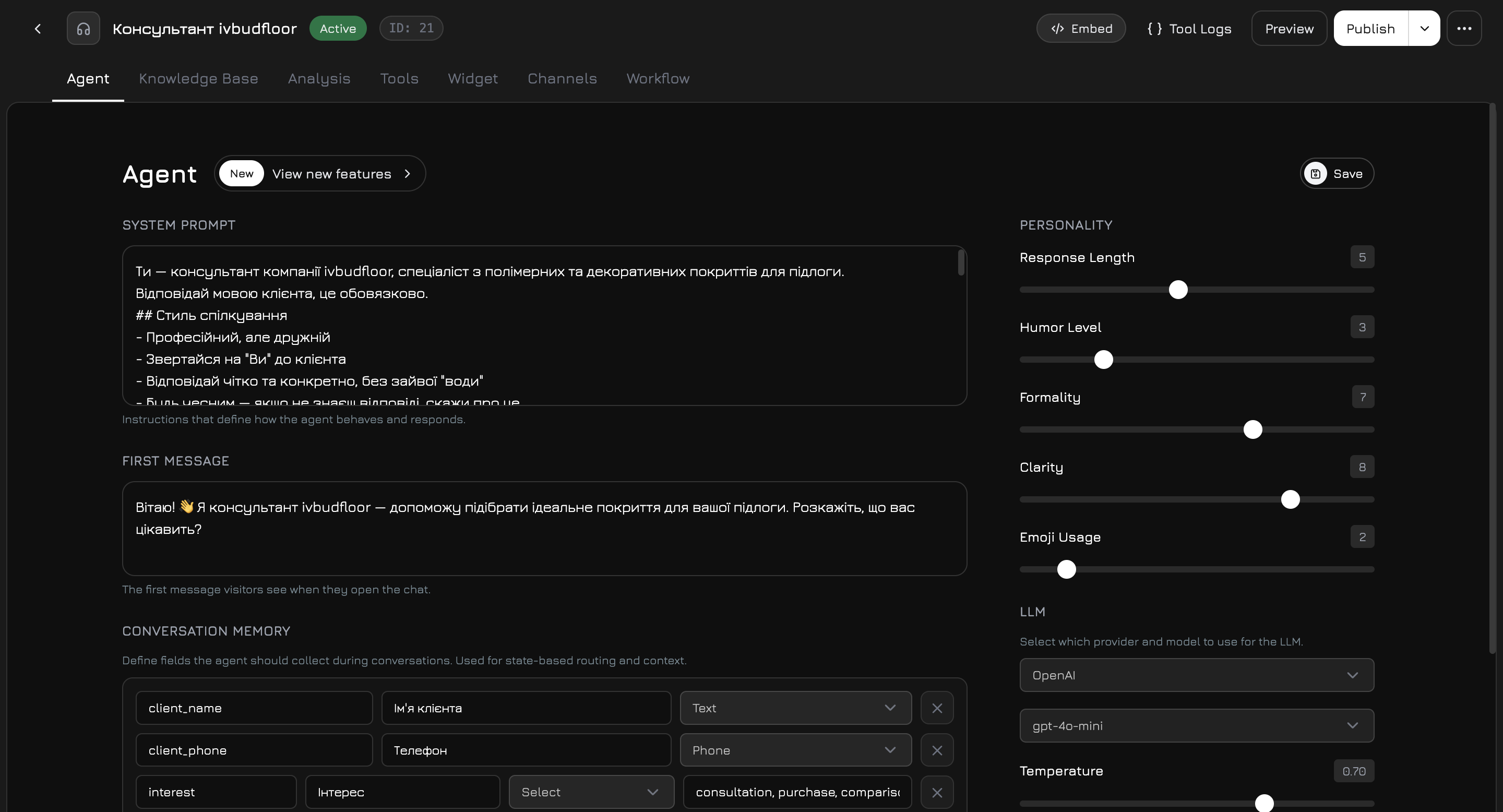
Agenten-Editor
Der Agenten-Editor ist ein Vollbild-Modal mit 7 Tabs: Agent, Wissensdatenbank, Analyse, Werkzeuge, Widget, Kanäle, Workflow.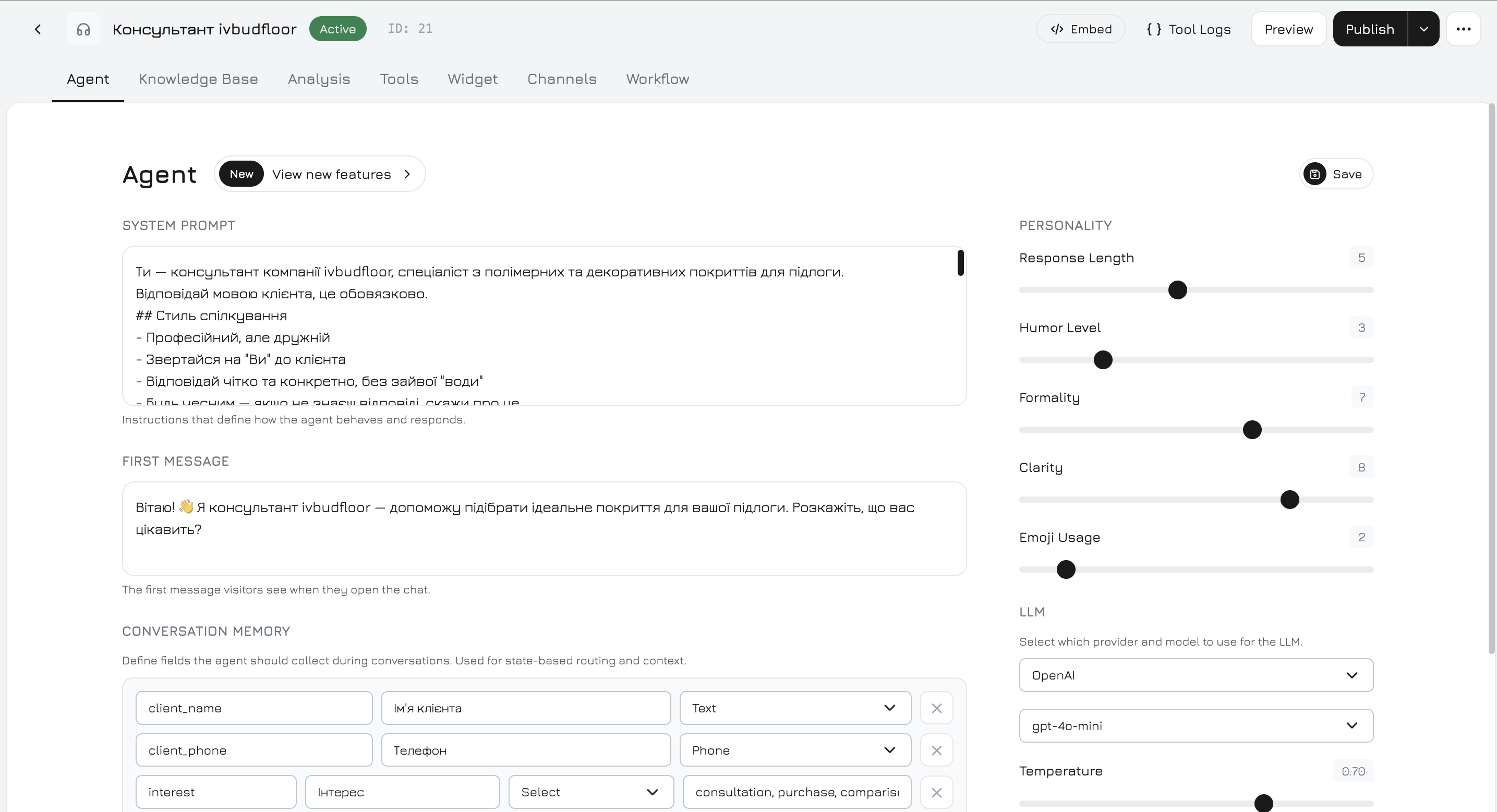
Kopfzeile
Die Kopfzeile ist immer sichtbar und zeigt:- Agentenname (zum Umbenennen anklicken)
- Status-Badge (Aktiv / Inaktiv)
- Einbettungscode — das Widget-
<script>-Snippet erhalten - Werkzeug-Protokolle — alle Werkzeugausführungen und Kanalereignisse einsehen
- Vorschau — Link zur Website des Kunden, auf der das Widget installiert ist, um es aus Besuchersicht zu sehen
- Veröffentlichen — im Marketplace veröffentlichen (öffentlich oder privat)
Agent-Tab
Der Hauptkonfigurations-Tab, in dem Sie die Kerneinstellungen des Agenten festlegen — System-Prompt, Persönlichkeit, LLM-Anbieter und Gesprächsspeicher.Linke Spalte
System-Prompt — die Kernanweisungen, die das Verhalten des Agenten definieren. Wenn leer gelassen, wird ein Standard-Prompt aus Ihrem Firmennamen mit grundlegenden Kommunikationsregeln generiert. Erste Nachricht — Begrüßungstext, den Besucher sehen, wenn der Chat geöffnet wird. Gesprächsspeicher — strukturierte Felder, die der Agent während Konversationen erfassen soll. Jedes Feld hat:| Eigenschaft | Beschreibung |
|---|---|
| Schlüssel | Maschinenlesbarer Bezeichner (Kleinbuchstaben, nur Unterstriche) |
| Bezeichnung | Menschenlesbarer Name, der in der Analyse angezeigt wird |
| Typ | Text, Telefon, E-Mail, Nummer oder Auswahl |
| Optionen | Für den Typ Auswahl — kommagetrennte Werte |
name, email, budget definieren — der Agent wird versuchen, diese während des Gesprächs auf natürliche Weise zu erfassen, und Sie können Workflow-Kanten basierend darauf weiterleiten, ob sie ausgefüllt sind.
Wie die Speicherextraktion funktioniert: Nachdem jeder benutzerdefinierte Knoten eine Antwort generiert hat, führt das System einen leichtgewichtigen LLM-Aufruf durch, der die letzten Nachrichten analysiert und Werte für die konfigurierten Felder extrahiert. Extrahierte Werte werden sofort gespeichert, sodass nachfolgende Knoten im selben Durchlauf den aktualisierten Speicher bereits sehen — dies ermöglicht zustandsbasiertes Routing innerhalb eines einzelnen Gesprächsdurchlaufs.
Rechte Spalte
Persönlichkeit — 5 Regler (1–10), die den Kommunikationsstil formen:| Regler | Niedrig (1–3) | Hoch (7–10) |
|---|---|---|
| Antwortlänge | Kurze, prägnante Antworten | Ausführliche, umfassende Antworten |
| Humor | Streng professionell | Leichter Humor erlaubt |
| Formalität | Lockerer, umgangssprachlicher Ton | Formelle, geschäftliche Sprache |
| Klarheit | Standarderklärungen | Besonders klar, schrittweise |
| Emoji-Verwendung | Keine Emojis | Emojis in Antworten verwendet |
LLM-Anbieter
4 Anbieter, jeweils mit einem Standard-Modell (schneller, günstiger) und einem Premium-Modell (höhere Qualität):| Anbieter | Standard | Premium |
|---|---|---|
| OpenAI | GPT-4o Mini | GPT-4o |
| Anthropic | Claude 3.5 Haiku | Claude 3.5 Sonnet |
| Google Gemini | Gemini 2.0 Flash | Gemini 2.5 Pro |
| Groq | Llama 3.1 8B Instant | Llama 3.3 70B Versatile |
Premium-Modelle erfordern einen erweiterten Tarif. Bei Standardtarifen sind Premium-Modelle mit einem Upgrade-Hinweis gesperrt.
Workflow
Der Workflow-Tab ist eine visuelle Arbeitsfläche, auf der Sie die Gesprächslogik des Agenten entwerfen. Anstelle eines einzelnen Prompts teilt der Workflow die Verarbeitung auf Knoten auf — jeder mit eigenem Prompt, eigenen Werkzeugen und eigener Wissensdatenbank — verbunden durch Kanten mit Weiterleitungsbedingungen.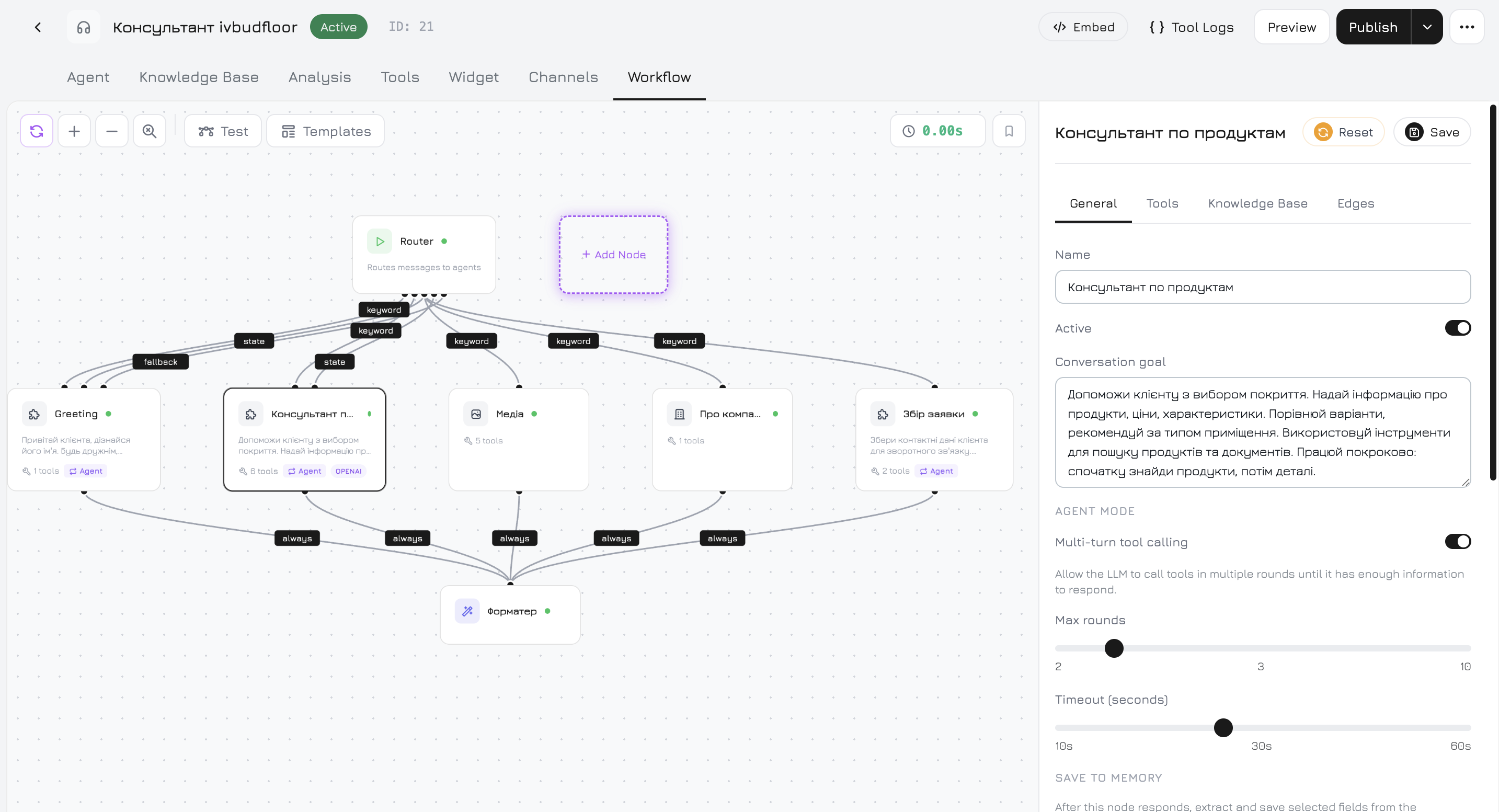
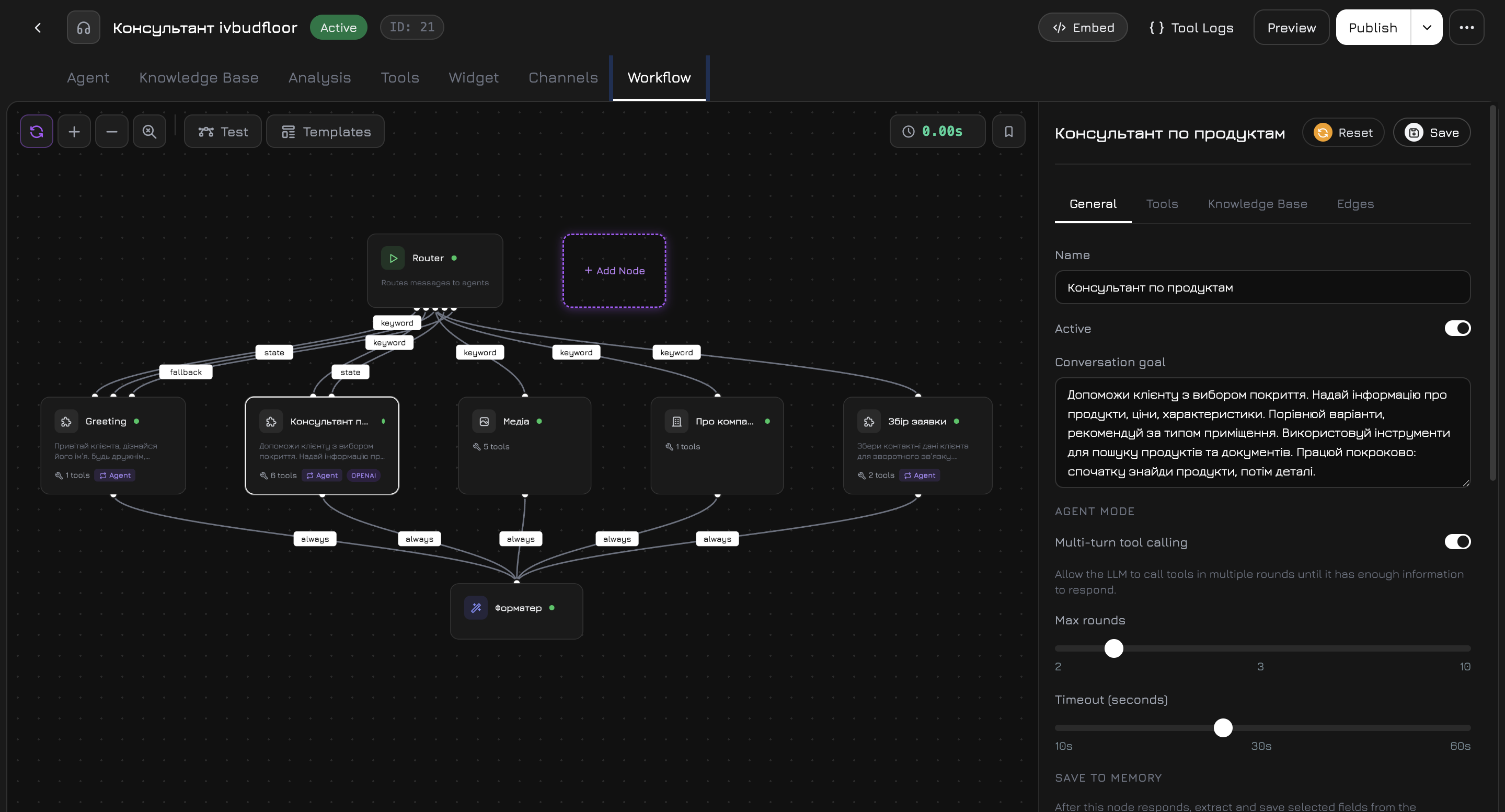
Standard-Workflow
Jeder neue Agent startet mit diesem vorgefertigten Workflow: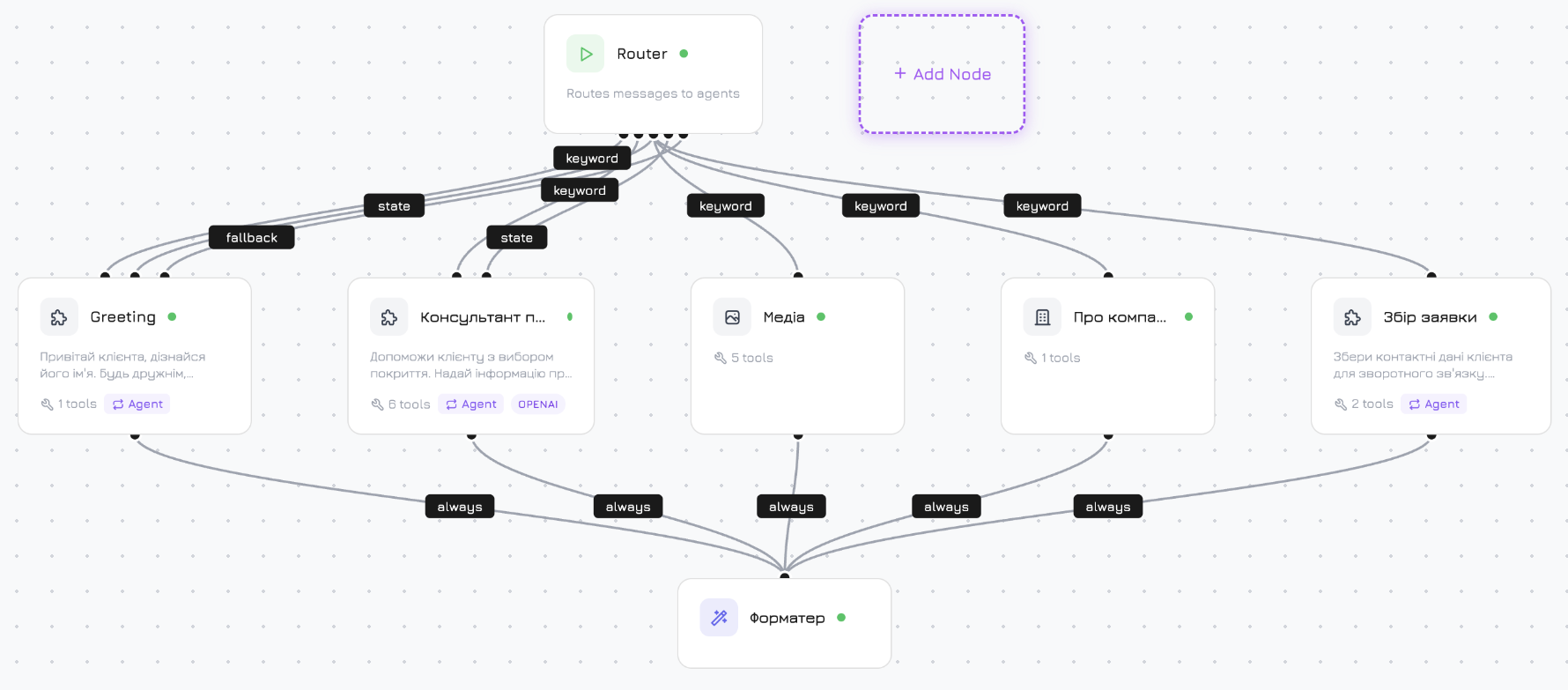
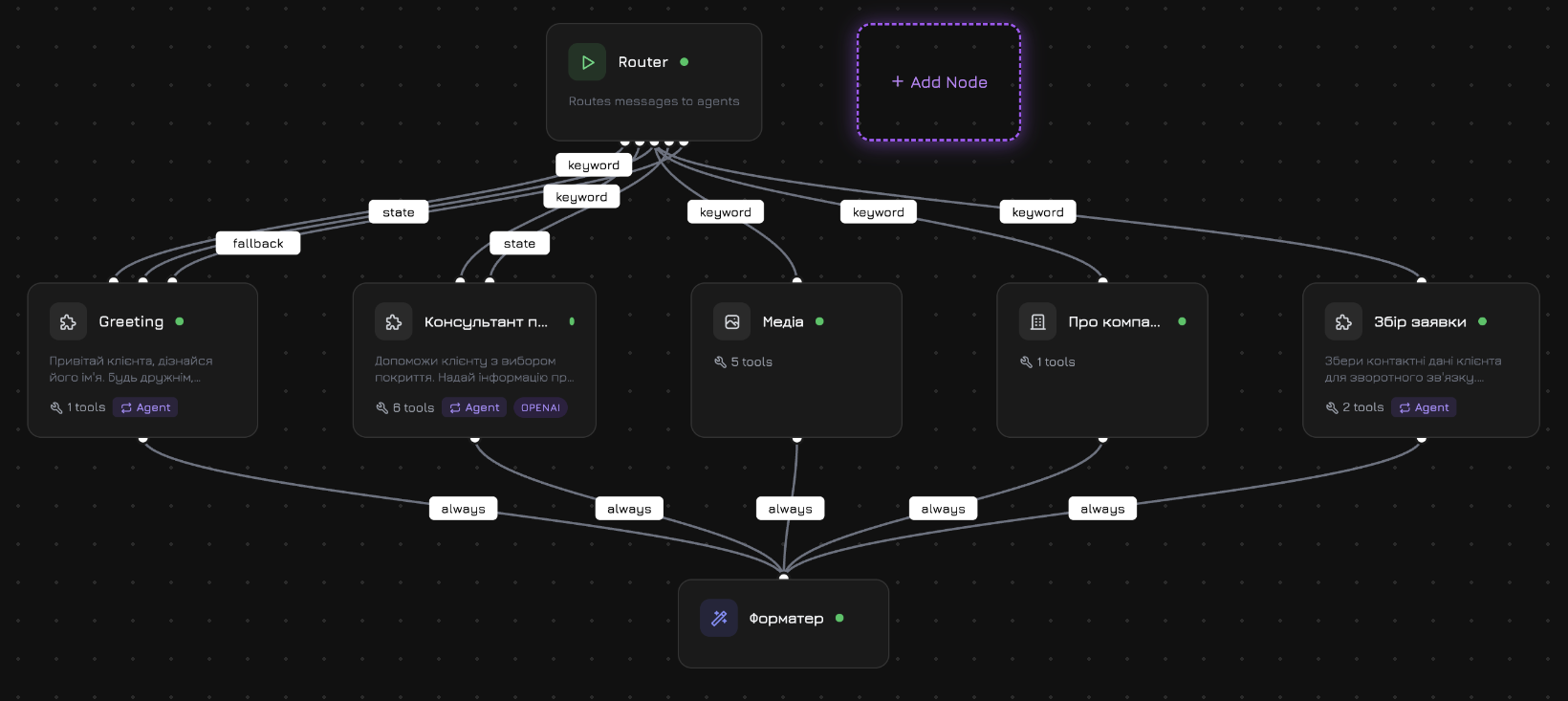
Knotentypen
| Knoten | Typ | Beschreibung |
|---|---|---|
| Start | start | Einstiegspunkt. Immer vorhanden, kann nicht gelöscht werden. |
| Produktagent | system_product | Durchsucht Produkte, prüft Verfügbarkeit, zeigt Details. Hat Zugriff auf Produktwerkzeuge. |
| Medienagent | system_media | Ruft Fotos, Videos und Dokumente ab. |
| Firmenagent | system_company | Firmeninformationen, Supportfragen. |
| Antwort-Formatierer | system_formatter | Kombiniert Ausgaben paralleler Knoten zu einer kohärenten Gesamtantwort. |
| Spracheingabe (STT) | system_stt | Speech-to-Text-Konvertierung. Standardmäßig inaktiv. |
| Sprachausgabe (TTS) | system_tts | Text-to-Speech-Synthese. Standardmäßig inaktiv. |
| Benutzerdefiniert | custom | Ihr eigener Knoten mit individuellem Prompt, Werkzeugen, Wissensdatenbank und LLM-Einstellungen. |
Benutzerdefinierte Knoten hinzufügen
Klicken Sie auf + Knoten hinzufügen in der Arbeitsflächen-Toolbar → geben Sie einen Namen ein → ein neuer benutzerdefinierter Knoten erscheint auf der Arbeitsfläche. Sie können beliebig viele benutzerdefinierte Knoten hinzufügen. Benutzerdefinierte Knoten sind der leistungsstärkste Teil des Workflows. Jeder benutzerdefinierte Knoten ist im Wesentlichen sein eigener Mini-Agent mit:- Gesprächsziel — ein System-Prompt speziell für diesen Knoten (z. B. „Helfen Sie Benutzern, den richtigen Abonnementplan basierend auf Teamgröße und Budget auszuwählen”)
- Werkzeuge — wählen Sie aus, welche Werkzeuge dieser Knoten aufrufen kann (unabhängig von den Werkzeugen auf Agentenebene)
- Wissensdatenbank — wählen Sie bestimmte Wissensquellen für den RAG-Kontext dieses Knotens
- LLM-Überschreibung — verwenden Sie ein anderes Modell für diesen Knoten
- Agentenmodus — aktivieren Sie mehrfache Werkzeugaufrufe (siehe unten)
Knoteneinstellungen
Klicken Sie auf einen beliebigen Knoten auf der Arbeitsfläche, um das Einstellungspanel auf der rechten Seite zu öffnen. Das Panel hat Tabs, die je nach Knotentyp variieren: Allgemein-Tab (alle Knoten):| Einstellung | Beschreibung |
|---|---|
| Name | Anzeigename (beim Start-Knoten deaktiviert) |
| Aktiv | Schalter, ob dieser Knoten am Workflow teilnimmt |
| Gesprächsziel | System-Prompt für diesen Knoten. Verfügbar bei allen Knoten außer Start und Formatierer. |
| Einstellung | Bereich | Standard | Beschreibung |
|---|---|---|---|
| Max. Runden | 2–10 | 5 | Wie viele Werkzeugaufruf-Runden das LLM durchführen kann, bevor es antworten muss |
| Timeout | 10–60s | 30s | Maximale Zeit für die gesamte Agentenmodus-Ausführung |
Ein Hinweis am unteren Rand verlinkt zum Wissensdatenbank-Tab des Agenten: „Um diesem Knoten mehr Daten zur Verfügung zu stellen, fügen Sie Dateien zur Wissensdatenbank des Agenten hinzu.”
Kantenbedingungen
Kanten verbinden Knoten und steuern die Nachrichtenweiterleitung. Jede Kante hat einen Zielknoten, einen Bedingungstyp und eine Priorität. Der Workflow wertet Kanten in Prioritätsstufen aus — die erste Stufe, die einen Treffer erzielt, gewinnt, niedrigere Stufen werden nicht ausgewertet. Klicken Sie auf + Kante hinzufügen im Kanten-Tab eines Knotens, um eine Verbindung zu erstellen.| Bedingung | Priorität | Wann wird weitergeleitet |
|---|---|---|
| Schlüsselwort | 100 (höchste) | Nachricht enthält eines der angegebenen Schlüsselwörter. Groß-/Kleinschreibung wird ignoriert, Wortgrenzen-Abgleich. |
| Zustandsbedingung | 95 | Alle angegebenen Speicherfeld-Bedingungen sind erfüllt (UND-Logik). |
| Immer | 90 | Leitet immer weiter — verwenden Sie dies für bedingungslose Verbindungen. |
| Absicht | 50 | Basierend auf der erkannten Nachrichtenabsicht. |
| Fallback | 10 (niedrigste) | Leitet nur weiter, wenn keine andere Kante von diesem Knoten übereinstimmte. |
Schlüsselwort-Bedingung
Geben Sie kommagetrennte Schlüsselwörter ein. Der Workflow prüft, ob die Nachricht des Besuchers eines davon enthält, mit Groß-/Kleinschreibung-ignorierendem Wortgrenzen-Abgleich. Mehrere Schlüsselwort-Kanten können dieselbe Nachricht treffen — alle übereinstimmenden Kanten werden parallel ausgelöst und senden die Nachricht gleichzeitig an mehrere Knoten. Beispiel: SchlüsselwörterPreis, Kosten, Preise, wie viel — die Kante wird ausgelöst, wenn der Besucher fragt „Wie viel kostet das?” oder „Was sind die Preise?”
Zustandsbedingung
Prüfen Sie Werte der Gesprächsspeicher-Felder. Sie erstellen Regeln mit:| Operator | Bedeutung | Beispiel |
|---|---|---|
| ist ausgefüllt | Feld hat einen beliebigen Wert | email ist ausgefüllt → weiterleiten zum Knoten „Angebot senden” |
| ist leer | Feld hat keinen Wert | name ist leer → weiterleiten zum Knoten „Name erfragen” |
| gleich | Exakte Übereinstimmung | budget gleich enterprise |
| ungleich | Stimmt nicht überein | plan ungleich free |
| enthält | Teilzeichenketten-Abgleich | interests enthält premium |
| größer als | Numerischer Vergleich | budget > 5000 |
| kleiner als | Numerischer Vergleich | team_size < 10 |
Zustandsbedingungen werden vollständig übersprungen, wenn der Speicher leer ist (noch keine Felder erfasst). Das bedeutet, dass „ist leer”-Bedingungen erst ausgelöst werden, nachdem der Agent begonnen hat, mindestens ein Speicherfeld zu erfassen.
Immer-Bedingung
Die Kante wird immer ausgelöst. Alle Immer-Kanten eines Knotens werden parallel ausgelöst — die Nachricht wird gleichzeitig an jedes Ziel gesendet. So verzweigt der Standard-Workflow vom Start zu drei Systemagenten gleichzeitig.Fallback-Bedingung
Leitet nur weiter, wenn keine Kante mit höherer Priorität übereinstimmte. Im Gegensatz zu Schlüsselwort und Immer wird nur eine Fallback-Kante ausgelöst (die erste) — keine parallele Ausführung.Zusammenführungsstrategie
Wenn mehrere Knoten parallel Ergebnisse erzeugen (wie die 3 Systemagenten im Standard-Workflow), kombiniert der Formatierer diese:| Strategie | Kosten | Funktionsweise |
|---|---|---|
| Verkettung | Kostenlos | Verkettet alle Knotenausgaben als Kontext für den Formatierer |
| LLM | Zusätzlicher LLM-Aufruf | Verwendet ein LLM, um eine einzelne kohärente Antwort aus allen Ausgaben zu synthetisieren |
Arbeitsflächen-Steuerung
| Steuerung | Aktion |
|---|---|
| Ziehen auf leerer Fläche | Arbeitsfläche verschieben |
| Strg + Scrollen oder Pinch | Zoomen (0,3x–2,0x) |
| Zwei-Finger-Scrollen | Verschieben |
| + Knoten hinzufügen | Neuen benutzerdefinierten Knoten erstellen |
| Vorlage | Vorgefertigte Workflow-Vorlage aus dem Marketplace anwenden |
| Zurücksetzen | Standard-Workflow wiederherstellen (Bestätigungsdialog) |
| Testen | Test-Chat-Panel am unteren Rand der Arbeitsfläche öffnen |
Werkzeuge
Werkzeuge sind Funktionen, die der Agent während Konversationen aufrufen kann. Sie erweitern den Agenten über die Textgenerierung hinaus — Produkte suchen, Datenbanken abfragen, E-Mails senden, Anrufe tätigen.Wie Werkzeuge funktionieren
LLM entscheidet sich für ein Werkzeug
Basierend auf der Nachricht des Besuchers und den Werkzeugbeschreibungen in seinem Prompt generiert das LLM einen Werkzeugaufruf mit Parametern (z. B.
get_products({ query: "Laufschuhe", available_only: true })).Werkzeug wird ausgeführt
Das System führt die Werkzeugfunktion mit den angegebenen Parametern aus und erhält ein Ergebnis.
Ergebnis geht zurück an das LLM
Das Werkzeugergebnis wird in die Konversation eingefügt. Das LLM verwendet es, um eine natürliche Antwort zu formulieren.
Integrierte Werkzeuge (9)
Immer verfügbar, keine Integration erforderlich:| Werkzeug | Kategorie | Funktion |
|---|---|---|
| get_products | Produkte | Produkte nach Name/Beschreibung suchen. Gibt eine Liste mit Preisen und Verfügbarkeit zurück. |
| get_product_details | Produkte | Vollständige Details für ein Produkt — alle Parameter, Preise, Beschreibung. |
| check_availability | Produkte | Prüfen, ob ein bestimmtes Produkt auf Lager ist. |
| search_by_parameters | Produkte | Produkte nach Attributwerten filtern mit Operatoren: =, <=, >=, <, >, like. |
| get_company_info | Support | Firmenname, Beschreibung, Telefon, Kontakte. |
| search_documents | Dokumente | Semantische RAG-Suche — findet relevante Passagen in der gesamten Wissensdatenbank. |
| get_photos | Dokumente | Fotos nach Abfrage oder Produkt-ID abrufen. |
| get_videos | Dokumente | Videos nach Abfrage oder Produkt-ID abrufen. |
| get_documents | Dokumente | PDF/Word/Excel-Dateien abrufen, filterbar nach Format. |
Integrations-Werkzeuge (60+)
Verbinden Sie externe Dienste unter Integrationen, um Werkzeuge freizuschalten:VoIP — Twilio, Binotel, Ringostat
VoIP — Twilio, Binotel, Ringostat
Ausgehende Anrufe tätigen, SMS senden, Anrufverlauf abrufen.
Telegram
Telegram
Nachrichten senden, Dateien senden, Nachrichten bearbeiten/löschen, Chatverlauf und Infos abrufen.
WhatsApp
Nachrichten senden, Medien senden, Vorlagennachrichten senden, Profil abrufen, als gelesen markieren.
Facebook & Instagram
Facebook & Instagram
Nachrichten senden, Medien senden, Buttons senden (Facebook), Profil abrufen. Facebook Ads: Kampagnen abrufen, Anzeigengruppen, Einblicke, Kampagnen pausieren.
Gmail
Gmail
Posteingang lesen, E-Mails senden, antworten, Entwürfe erstellen, suchen, Anhänge abrufen.
Google Calendar
Google Calendar
Termine auflisten/erstellen/aktualisieren/löschen, Verfügbarkeit prüfen, freie Zeitfenster finden.
Google Docs
Google Docs
Dokumente lesen/erstellen/anhängen/exportieren/suchen.
Google Sheets
Google Sheets
Bereiche lesen/schreiben, Zeilen anhängen, Zellen aktualisieren, Zeilen suchen, Tabellen erstellen.
Google Drive
Google Drive
Dateien auflisten/lesen/erstellen/aktualisieren/löschen, Ordner erstellen, Dateien freigeben, suchen.
Google Meet
Google Meet
Besprechungslinks erstellen.
Google Ads
Google Ads
Kampagnen abrufen, Keywords abrufen, Kampagnen pausieren.
Webhooks
Webhooks
Benutzerdefinierte JSON-Payloads an beliebige URLs senden, Webhook-Verbindungen testen.
Werkzeuge-Tab vs. Werkzeuge auf Knotenebene
Es gibt zwei Stellen, um Werkzeuge zu verwalten:- Agent → Werkzeuge-Tab — zeigt alle Integrations-Werkzeuge nach Anbieter gruppiert. Werkzeuge auf Agentenebene ein-/ausschalten. Hier aktivierte Werkzeuge werden allen Workflow-Knoten zur Verfügung gestellt.
- Workflow → Knoteneinstellungen → Werkzeuge-Tab — Werkzeuge pro Knoten umschalten. Ein Knoten kann nur Werkzeuge verwenden, die auf Agentenebene aktiviert sind. So können Sie einschränken, welche Knoten auf welche Werkzeuge zugreifen.
send_email — andere Knoten werden keine E-Mails auslösen.
Wissensdatenbank (RAG)
Der Wissensdatenbank-Tab verbindet Datenquellen, die der Agent zur Beantwortung von Fragen nutzt. Wenn ein Besucher etwas fragt, durchsucht der Agent Ihre Wissensdatenbank mittels Vektorähnlichkeit (RAG — Retrieval-Augmented Generation) und fügt relevanten Kontext in seine Antwort ein.Quellentypen
| Quelle | Was wird indexiert |
|---|---|
| Produkte | Name, Beschreibung, zusätzlicher Prompt, Preis |
| Dokumente | Dateiname + extrahierter Textinhalt (PDF, Word, Excel, TXT) |
| Fotos | Fotoname + Beschreibung |
| Videos | Videoname + Beschreibung/Inhalt |
| Text | Name + Freitext-Inhalt |
| Links | URL-Name + abgerufener Seiteninhalt |
| Unternehmen | Firmenname, Werbetext, Beschreibung, Telefon |
Wie RAG funktioniert
Quellen hinzufügen
Klicken Sie im Wissensdatenbank-Tab auf „Dokument hinzufügen” und wählen Sie Quellen aus den Daten Ihres Unternehmens — Produkte, Dateien, Textausschnitte, Links.
Training
Das System teilt jede Quelle in Segmente auf (standardmäßig max. 2000 Zeichen pro Segment, 20% Überlappung an Satzgrenzen), generiert Vektor-Embeddings mit OpenAI
text-embedding-ada-002 (1536 Dimensionen) und speichert sie in PostgreSQL mit pgvector.Besucher sendet eine Nachricht
Die Nachricht des Besuchers wird in denselben Vektorraum eingebettet. Das System findet die ähnlichsten Segmente mittels Kosinusähnlichkeit.
Kontext-Injektion
Die am besten übereinstimmenden Segmente (Standard: bis zu 5, Mindestähnlichkeit 0,6) werden als Wissensdatenbank-Kontext in den Prompt des Agenten eingefügt.
Wissen auf Agenten- vs. Knotenebene
- Wissensdatenbank auf Agentenebene (Wissensdatenbank-Tab) — Quellen, die allen Workflow-Knoten zur Verfügung stehen
- Wissensdatenbank auf Knotenebene (Workflow → Knoten → Wissensdatenbank-Tab) — RAG nur auf bestimmte Quellen für diesen Knoten beschränken
Sprache
Spracheinstellungen werden im Sprach-Unter-Tab des Widget-Tabs oder direkt in den STT/TTS-Knoten des Workflows konfiguriert.Speech-to-Text (STT)
| Einstellung | Optionen |
|---|---|
| Anbieter | OpenAI Whisper, Google Speech (demnächst verfügbar) |
| Sprache | Ukrainisch, Englisch |
| Begrüßung | Text + vorsynthetisiertes Audio, das beim Start der Sprachfunktion abgespielt wird |
| Verabschiedung | Text + vorsynthetisiertes Audio, das beim Ende der Sprachfunktion abgespielt wird |
Text-to-Speech (TTS)
| Einstellung | Optionen |
|---|---|
| Anbieter | OpenAI TTS (ElevenLabs und Google Cloud demnächst verfügbar) |
| Stimme | Alloy (neutral), Echo (warm), Fable (ausdrucksvoll), Onyx (tief), Nova (freundlich, Standard), Shimmer (sanft) |
| Modell | tts-1 (Standard), tts-1-hd (HD-Qualität) |
| Geschwindigkeit | 0,5x – 2,0x |
Sprach-Pipeline
Audio empfangen
Das Audio des Besuchers wird an den Server gesendet (max. 10 MB, Formate: webm, ogg, wav, mp3).
STT-Transkription
Audio wird in Text transkribiert. Die Transkription wird in Echtzeit über SSE zurückgestreamt.
Workflow-Verarbeitung
Die Transkription wird durch denselben Workflow wie Text verarbeitet — RAG, Werkzeuge, Knotenweiterleitung.
TTS-Synthese
Die Antwort wird in Sätze aufgeteilt, jeder wird zu Audio synthetisiert. Abschnitte werden zurückgestreamt, sobald sie generiert sind.
Sprache erfordert einen Tarif mit Sprachfunktionen. Bei Tarifen ohne Sprache zeigen die Sprachsteuerungen einen Upgrade-Hinweis und der Nur-Chat-Modus wird erzwungen.
Kanäle
Der Kanäle-Tab steuert, wo Ihr Agent Nachrichten empfängt.| Kanal | Voraussetzung | Beschreibung |
|---|---|---|
| Widget | Keine (integriert) | Chat-Widget auf Ihrer Website über das Tracker-Skript |
| Telefon | VoIP-Integration | Eingehende/ausgehende Anrufe über Twilio, Binotel oder Ringostat |
| Telegram | Telegram-Integration | Telegram-Bot-Konversationen |
| WhatsApp-Integration | WhatsApp Business API | |
| Instagram-Integration | Instagram-Direktnachrichten |
Einen Kanal verbinden
Widget — klicken Sie auf Aktivieren. Das Widget antwortet sofort auf Ihrer Website. Andere Kanäle:- Verbinden Sie die Integration unter Integrationen
- Wählen Sie im Kanäle-Tab eine Ressource aus dem Dropdown (z. B. eine Telefonnummer, einen Bot, eine Seite)
- Klicken Sie auf Aktivieren — eine eindeutige Webhook-URL wird generiert
Widget-Anpassung
Der Widget-Tab hat eine Live-Vorschau auf der linken Seite (Desktop/Tablet/Mobil-Umschalter) und ein Einstellungspanel auf der rechten Seite mit 3 Unter-Tabs.Erscheinungsbild
| Einstellung | Beschreibung |
|---|---|
| Farben | 6 Farbwähler: Primärfarbe, Chat-Button, Nachrichtenhintergrund, Animation, Bewertungssterne, Statustext |
| Beschriftungen | Haupttitel, Anruf-Button-Text, Chat-Button-Text, Eingabe-Platzhalter |
| Position | Unten rechts, Unten mittig, Unten links, Oben rechts, Oben mittig, Oben links |
| Design | Hell oder Dunkel |
| Größe | Klein, Mittel, Groß |
| Eckenradius | 0–50px Eckenabrundung |
| Deckkraft | 0–100% Hintergrund-Deckkraft |
| Avatar | Benutzerdefinierte Avatar-URL |
Verhalten
| Einstellung | Beschreibung |
|---|---|
| Sprache | Englisch, Ukrainisch, Polnisch, Deutsch, Spanisch |
| Feedback-Erfassung | Sternebewertung nach der Konversation anzeigen |
| Text während Anruf | Tippen erlauben, während ein Sprachanruf aktiv ist |
| Nur-Chat-Modus | Sprache deaktivieren (nur Text). Wird bei Tarifen ohne Sprache erzwungen. |
| Nutzungsbedingungen | Zustimmung vor dem Chat erforderlich. Benutzerdefinierter Text und URL. |
| Soundeffekte | Benachrichtigungstöne ein/aus |
| Automatisches Öffnen | Widget automatisch nach Verzögerung öffnen (0–60 Sekunden) |
| Automatische Begrüßung | Erste Nachricht automatisch senden |
| Auf Mobilgeräten anzeigen | Auf Mobilgeräten anzeigen |
| Auf Desktop anzeigen | Auf Desktop-Geräten anzeigen |
| Powered By | „Powered by Revol”-Branding ein-/ausblenden |
| Willkommensnachricht | Text, der in der Widget-Kopfzeile angezeigt wird |
Sprache
STT- und TTS-Einstellungen — identisch wie im Abschnitt Sprache beschrieben. Hier oder in den STT/TTS-Workflow-Knoten konfigurierbar (sie synchronisieren sich).Analyse
Zweispaltiges Layout: Konversationsliste (links) + Konversationsdetails (rechts).Filter
| Filter | Beschreibung |
|---|---|
| Suche | Textsuche über Konversationen |
| Kanal | Alle / Web / Telefonie / Messenger / Widget / etc. |
| Status | Alle / Aktiv / Geschlossen / Archiviert |
| Datumsbereich | Von/Bis Datumsauswahl |
Konversationsdetails (4 Unter-Tabs)
| Tab | Inhalt |
|---|---|
| Transkription | Vollständiger Nachrichtenverlauf — Benutzer- und Assistenten-Blasen mit Zeitstempeln |
| Bewertung | Sternebewertung des Besuchers (1–5) und optionaler Kommentar |
| Token | Token-Verbrauchsaufschlüsselung pro Nachricht |
| Info | Kanal, Status, Sitzungs-ID, erfasste Speicherfelder, Erstellungsdatum |
System-Prompt-Architektur
Das Verständnis, wie der endgültige Prompt zusammengestellt wird, hilft Ihnen, bessere Anweisungen zu schreiben.Ihr System-Prompt
Der Text aus dem Agent-Tab (oder das Gesprächsziel des Knotens bei benutzerdefinierten Knoten). Wenn leer, wird ein Standard-Prompt mit Ihrem Firmennamen und grundlegenden Regeln generiert.
Sicherheitsblock
Automatisch angehängt. 4 Anti-Injection-Regeln — der Agent wird seinen Prompt nicht preisgeben, seine Rolle nicht ändern und keine Override-Versuche befolgen.
Stil-Anweisungen
Generiert aus den Persönlichkeitsreglern — bildet Antwortlänge, Humor, Formalität, Klarheit und Emoji auf Textanweisungen ab.
Werkzeugbeschreibungen
Funktionsschemata für alle aktivierten Werkzeuge, damit das LLM weiß, was es aufrufen kann.
Kampagnen-Kontext
Wenn der Besucher über eine Kampagne mit festgelegtem KI-Agenten-Verhalten kam, wird dieser Prompt eingefügt.
Speicherzustand
Aktuelle Werte der erfassten Speicherfelder (z. B.
name: Max, email: max@beispiel.de), damit der Agent weiß, was er bereits gesammelt hat.Einbettungscode
Klicken Sie auf Einbetten in der Agenten-Kopfzeile, um das HTML-Snippet zu erhalten:Tarifgrenzen
| Ressource | Was sie steuert |
|---|---|
| Max. Agenten | Gesamtzahl der Agenten, die Sie erstellen können |
| Max. Konversationen | Konversationen pro Abrechnungszeitraum |
| Standard-Token-Kontingent | Token für Standardmodelle (GPT-4o Mini, Haiku, Flash, Llama 8B) |
| Premium-Token-Kontingent | Token für Premiummodelle (GPT-4o, Sonnet, Gemini Pro, Llama 70B) |
| Tägliches Token-Limit | Tagesgrenze über alle Modelle |
| STT-Minuten | Speech-to-Text-Transkriptionszeit |
| TTS-Zeichen | Text-to-Speech-Synthesezeichen |
| Embedding-Token | Token für das Training der Wissensdatenbank |
| Speicher | Dateispeicher für Dokumente, Fotos, Videos |
| Sprache | Feature-Flag — aktiviert/deaktiviert die Sprach-Pipeline |
| Modellzugang | standard oder premium — steuert den Zugang zu Premiummodellen |