> ## Documentation Index
> Fetch the complete documentation index at: https://revolai.mintlify.site/llms.txt
> Use this file to discover all available pages before exploring further.
# База знань
> Навчайте вашого агента за допомогою документів та контенту
## Огляд
База знань використовує **RAG (Retrieval-Augmented Generation)**, щоб надати вашому агенту доступ до бізнес-контенту. Документи розбиваються на частини (chunks), перетворюються на векторні embeddings та зберігаються для семантичного пошуку.
Перейдіть на вкладку **Knowledge Base** в панелі агента. Тут ви обираєте, які саме дані агент використовуватиме для відповідей.
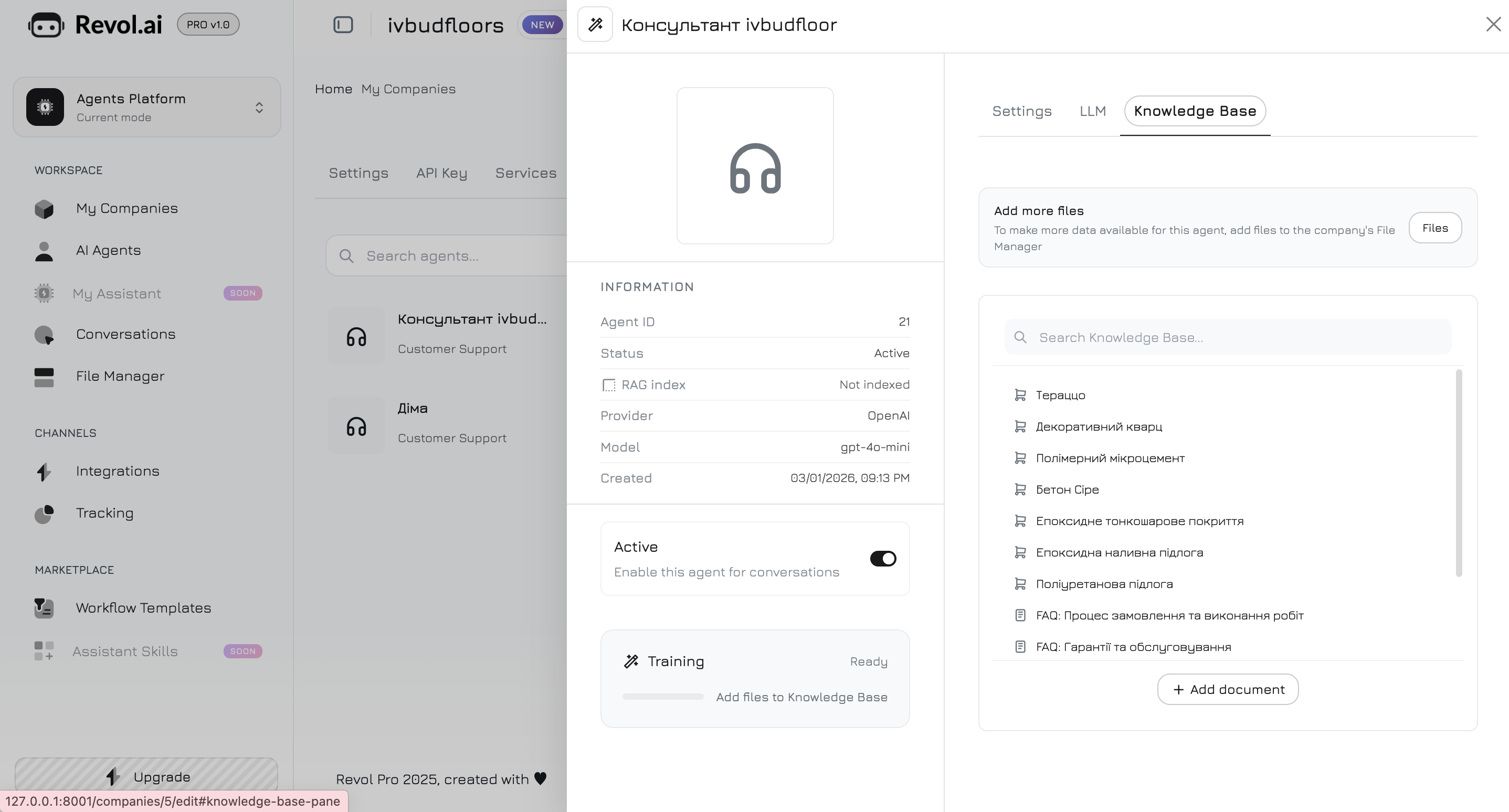
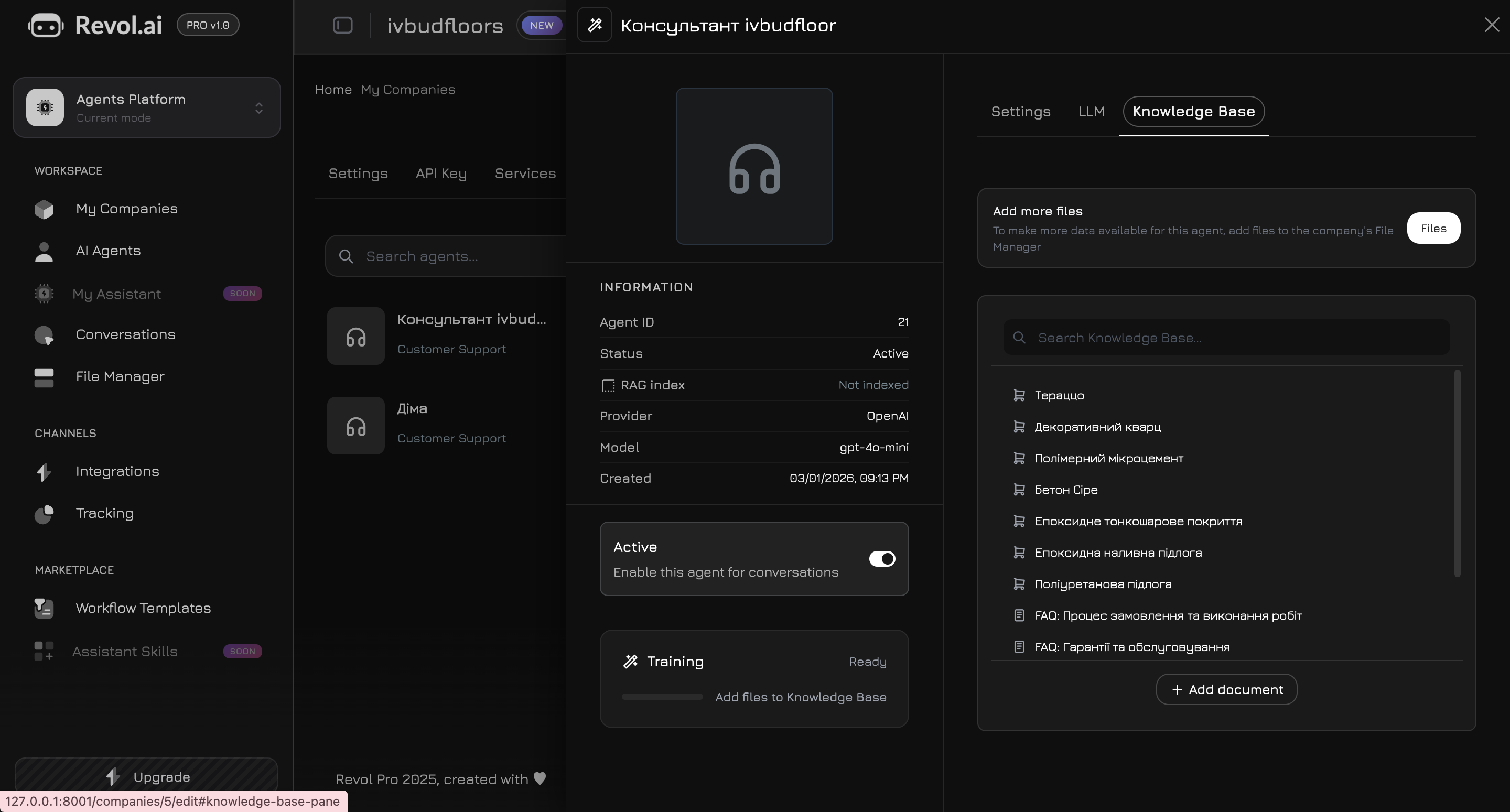 ## Додавання контенту
### Документи
Завантажуйте файли у підтримуваних форматах:
* PDF
* DOCX
* TXT
### URL-адреси
Вкажіть URL-адреси веб-сторінок. Revol збере контент та додасть його до бази знань.
### Текст
Додавайте контент безпосередньо як текстові блоки.
## Як працює RAG
Ви завантажуєте документ або додаєте контент.
Контент розбивається на керовані частини (chunks).
Кожна частина перетворюється на векторний embedding за допомогою обраної моделі ембедінгу.
Embeddings зберігаються в PostgreSQL з розширенням pgvector.
Коли користувач ставить питання, найбільш подібні частини отримуються за допомогою косинусної подібності (cosine similarity).
Отримані частини додаються до промпту LLM як контекст.
## Налаштування RAG
Відкрийте налаштування RAG через **іконку шестеренки** (⚙) в панелі зберігання бази знань. Всі налаштування зберігаються на рівні компанії та автоматично.
### Модель ембедінгу
Оберіть модель для перетворення тексту у векторні ембедінги:
| Модель | Провайдер | Розмірність | Ціна | Найкраще для |
| ---------------------- | --------- | ----------- | ----------------- | ------------------------------------------ |
| text-embedding-3-small | OpenAI | 1536 | \$0.02/1M токенів | Загальне використання, англійський контент |
| text-embedding-3-large | OpenAI | 1536 | \$0.13/1M токенів | Вища точність, англійський контент |
| BGE-M3 | DeepInfra | 1024 | \$0.01/1M токенів | Мультимовний контент (100+ мов) |
Зміна моделі ембедінгу **видаляє всі існуючі ембедінги** компанії. Після перемикання потрібно перенавчити всіх агентів. Перед застосуванням зміни з'явиться діалог підтвердження.
### Ліміт чанків
Скільки текстових фрагментів повертається за один RAG-пошук (1–20). За замовчуванням: **5**.
Більше значення дає більше контексту для LLM, але збільшує використання токенів.
### Ліміт символів
Максимум символів на фрагмент при розбитті документів (500–10,000). За замовчуванням: **1,500**.
Менші фрагменти дають точніший пошук. Більші — зберігають більше контексту в кожному результаті.
### Перекриття чанків
Перекриття між послідовними фрагментами (0–40%). За замовчуванням: **15%**.
Перекриття гарантує, що важливий контекст на межах фрагментів не буде втрачено. Більше перекриття створює більше чанків та використовує більше сховища.
### Поріг подібності
Мінімальна косинусна подібність для включення результату (0.1–1.0). За замовчуванням: **0.35**.
Нижчі значення повертають більше результатів (краща повнота). Вищі — лише високорелевантні результати (краща точність). Для мультимовного контенту використовуйте нижчі пороги (0.3–0.4).
## Ліміти зберігання
| План | Документи бази знань | Embedding токени |
| ------------ | -------------------- | ---------------- |
| Free | 10 | 100,000 |
| Premium | 100 | 1,000,000 |
| Professional | 1,000 | 5,000,000 |
***
## Генерація бази знань за допомогою Claude Code
Якщо у вас є документація проекту (сторінки сайту, портал документації, README файли, wiki) і ви хочете перетворити її на структуровану базу знань для вашого AI-агента Revol, ви можете використати **Claude Code** для аналізу документації та генерації готових до завантаження TXT файлів.
```text theme={null}
# Інструкція: Генерація файлів бази знань із документації
## Контекст
Я використовую Revol — платформу для створення AI-агентів
продажів з RAG (Retrieval-Augmented Generation). Мій агент
відповідає на питання, використовуючи базу знань: завантажені
файли розбиваються на частини (chunks, макс. 2000 символів,
20% перекриття), перетворюються на вектори через OpenAI
text-embedding-ada-002 (1536 вимірів), зберігаються в
PostgreSQL з pgvector і шукаються за косинусною подібністю
під час інференсу.
Мені потрібно перетворити документацію мого проекту на набір
.txt файлів, оптимізованих для цього RAG-пайплайну — щоб
агент міг знаходити й цитувати точні відповіді.
## Як працює RAG-розбиття (важливо для структури файлів)
- Кожен файл розбивається на частини по ~2000 символів з 20%
перекриттям на межах речень
- Назва файлу стає частиною метаданих embedding — використовуйте
описові назви, щоб система могла ідентифікувати джерело
- Короткі, сфокусовані файли працюють краще, ніж один великий
- Кожна частина (chunk) має бути самодостатньою — читач повинен
розуміти частину без оточуючого тексту
- Структурований контент (списки, таблиці як текст, чіткі
заголовки) розбивається краще, ніж суцільні абзаци
## Твоє завдання
### Крок 1: Аналіз усієї документації
Прочитай кожен файл документації проекту. Для кожного файлу
визнач:
1. Тему, яку він охоплює
2. Ключові факти, налаштування, конфігурації та значення
3. Покрокові процедури
4. Описи функцій з конкретикою (ліміти, опції, формати)
5. Тарифи, плани та квоти (якщо є)
6. Технічні деталі (API, параметри, інтеграції)
### Крок 2: Планування структури файлів
Згрупуй пов'язаний контент за логічними темами. Кожен файл
має охоплювати ОДНУ цілісну тему. Цільові розміри файлів:
- Ідеально: 2 000–6 000 символів на файл (1–3 chunks)
- Максимум: 10 000 символів (5 chunks)
- Якщо тема більша — розбий на підтеми
Конвенція іменування: {Назва-Теми}.txt
- Описові назви з дефісами
- Без числових префіксів (порядок не важливий для RAG)
- Назва має натякати на вміст для метаданих
Приклади:
- Platform-Overview.txt
- Getting-Started.txt
- Pricing-Plans.txt
- API-Authentication.txt
- Webhook-Integration.txt
### Крок 3: Написання файлів
Для кожного файлу дотримуйся цих правил:
Правила контенту:
- Починай з чіткого заголовка теми як звичайний текст
- Пиши звичайним текстом — без Markdown, без HTML,
без JSX-компонентів
- Перетворюй таблиці на читабельні списки або пари ключ-значення
- Перетворюй покрокові інструкції на нумеровані списки
- Включай конкретні значення: числа, ліміти, ціни, опції,
значення за замовчуванням, формати, URL
- Кожен абзац або розділ має бути зрозумілим окремо
(самодостатні chunks)
- Видаляй навігаційні елементи, посилання "Далі" та
перехресні посилання без інформаційної цінності
- Зберігай мову оригіналу документації
Оптимізація для RAG:
- Виноси важливу інформацію на початок — спочатку відповідь,
потім пояснення
- Використовуй єдину термінологію в усіх файлах
- Природно повторюй ключові терміни, щоб вони з'являлися
в декількох chunks (покращує пошук)
- Для функцій з налаштуваннями: вказуй назву, тип, значення
за замовчуванням, опції та опис
- Для інтеграцій: вказуй провайдера, метод авторизації,
кроки налаштування, доступні інструменти/функції
Що виключати:
- Скріншоти та посилання на зображення
- Розмітку UI-компонентів (tabs, accordions, cards, frames)
- Посилання "Див. також" та навігаційні блоки
- Декоративний текст та маркетинговий вміст
- Дублікат контенту (не повторюй одну інформацію в різних
файлах)
### Крок 4: Створення результату
1. Створи тимчасову директорію (напр., temp-knowledge-base/)
2. Запиши всі .txt файли в неї
3. Перелічи всі файли з розмірами та описами тем
4. Надай підсумок: загальна кількість файлів і розмір
## Опціонально: Генерація сідера Workflow-агента
Якщо проект використовує Revol і тобі також потрібно створити
AI-агента з workflow для відповідей на запитання щодо цієї
документації, згенеруй Laravel database seeder, який:
1. Створює AiAgent з:
- Відповідним system prompt для підтримки документації
- LLM: gpt-4o-mini, temperature: 0.3 (точність)
- Personality: висока ясність (8-9), висока формальність (6-7),
низький гумор (2-3), мало емодзі (1-2)
2. Будує Smart Router workflow:
- Start-нода з keyword-edges до нод-експертів
- 3-6 кастомних нод "експертів", кожна для групи тем
- Кожен експерт має свій conversation_goal з описом домену
- Кожен експерт має інструменти search_documents + get_company_info
- Один fallback-edge до ноди General Assistant
- Всі експерти з'єднані з Formatter-нодою
- Voice-ноди (STT/TTS) неактивні за замовчуванням
3. Ключові слова на edges мають відповідати природній лексиці,
яку використовують користувачі при запитаннях з кожної теми
## Вхідні дані
Моя документація знаходиться тут: [ШЛЯХ АБО URL]
Назва проекту: [НАЗВА]
Опис проекту: [КОРОТКИЙ ОПИС]
Target company_id для сідера: [ID або пропустити сідер]
```
Цей промпт найкраще працює з комплексними порталами документації, документацією продуктів, довідниками API та базами знань. Згенеровані .txt файли готові для завантаження безпосередньо у File Manager Revol — просто перетягніть та натисніть **Train**.
## Додавання контенту
### Документи
Завантажуйте файли у підтримуваних форматах:
* PDF
* DOCX
* TXT
### URL-адреси
Вкажіть URL-адреси веб-сторінок. Revol збере контент та додасть його до бази знань.
### Текст
Додавайте контент безпосередньо як текстові блоки.
## Як працює RAG
Ви завантажуєте документ або додаєте контент.
Контент розбивається на керовані частини (chunks).
Кожна частина перетворюється на векторний embedding за допомогою обраної моделі ембедінгу.
Embeddings зберігаються в PostgreSQL з розширенням pgvector.
Коли користувач ставить питання, найбільш подібні частини отримуються за допомогою косинусної подібності (cosine similarity).
Отримані частини додаються до промпту LLM як контекст.
## Налаштування RAG
Відкрийте налаштування RAG через **іконку шестеренки** (⚙) в панелі зберігання бази знань. Всі налаштування зберігаються на рівні компанії та автоматично.
### Модель ембедінгу
Оберіть модель для перетворення тексту у векторні ембедінги:
| Модель | Провайдер | Розмірність | Ціна | Найкраще для |
| ---------------------- | --------- | ----------- | ----------------- | ------------------------------------------ |
| text-embedding-3-small | OpenAI | 1536 | \$0.02/1M токенів | Загальне використання, англійський контент |
| text-embedding-3-large | OpenAI | 1536 | \$0.13/1M токенів | Вища точність, англійський контент |
| BGE-M3 | DeepInfra | 1024 | \$0.01/1M токенів | Мультимовний контент (100+ мов) |
Зміна моделі ембедінгу **видаляє всі існуючі ембедінги** компанії. Після перемикання потрібно перенавчити всіх агентів. Перед застосуванням зміни з'явиться діалог підтвердження.
### Ліміт чанків
Скільки текстових фрагментів повертається за один RAG-пошук (1–20). За замовчуванням: **5**.
Більше значення дає більше контексту для LLM, але збільшує використання токенів.
### Ліміт символів
Максимум символів на фрагмент при розбитті документів (500–10,000). За замовчуванням: **1,500**.
Менші фрагменти дають точніший пошук. Більші — зберігають більше контексту в кожному результаті.
### Перекриття чанків
Перекриття між послідовними фрагментами (0–40%). За замовчуванням: **15%**.
Перекриття гарантує, що важливий контекст на межах фрагментів не буде втрачено. Більше перекриття створює більше чанків та використовує більше сховища.
### Поріг подібності
Мінімальна косинусна подібність для включення результату (0.1–1.0). За замовчуванням: **0.35**.
Нижчі значення повертають більше результатів (краща повнота). Вищі — лише високорелевантні результати (краща точність). Для мультимовного контенту використовуйте нижчі пороги (0.3–0.4).
## Ліміти зберігання
| План | Документи бази знань | Embedding токени |
| ------------ | -------------------- | ---------------- |
| Free | 10 | 100,000 |
| Premium | 100 | 1,000,000 |
| Professional | 1,000 | 5,000,000 |
***
## Генерація бази знань за допомогою Claude Code
Якщо у вас є документація проекту (сторінки сайту, портал документації, README файли, wiki) і ви хочете перетворити її на структуровану базу знань для вашого AI-агента Revol, ви можете використати **Claude Code** для аналізу документації та генерації готових до завантаження TXT файлів.
```text theme={null}
# Інструкція: Генерація файлів бази знань із документації
## Контекст
Я використовую Revol — платформу для створення AI-агентів
продажів з RAG (Retrieval-Augmented Generation). Мій агент
відповідає на питання, використовуючи базу знань: завантажені
файли розбиваються на частини (chunks, макс. 2000 символів,
20% перекриття), перетворюються на вектори через OpenAI
text-embedding-ada-002 (1536 вимірів), зберігаються в
PostgreSQL з pgvector і шукаються за косинусною подібністю
під час інференсу.
Мені потрібно перетворити документацію мого проекту на набір
.txt файлів, оптимізованих для цього RAG-пайплайну — щоб
агент міг знаходити й цитувати точні відповіді.
## Як працює RAG-розбиття (важливо для структури файлів)
- Кожен файл розбивається на частини по ~2000 символів з 20%
перекриттям на межах речень
- Назва файлу стає частиною метаданих embedding — використовуйте
описові назви, щоб система могла ідентифікувати джерело
- Короткі, сфокусовані файли працюють краще, ніж один великий
- Кожна частина (chunk) має бути самодостатньою — читач повинен
розуміти частину без оточуючого тексту
- Структурований контент (списки, таблиці як текст, чіткі
заголовки) розбивається краще, ніж суцільні абзаци
## Твоє завдання
### Крок 1: Аналіз усієї документації
Прочитай кожен файл документації проекту. Для кожного файлу
визнач:
1. Тему, яку він охоплює
2. Ключові факти, налаштування, конфігурації та значення
3. Покрокові процедури
4. Описи функцій з конкретикою (ліміти, опції, формати)
5. Тарифи, плани та квоти (якщо є)
6. Технічні деталі (API, параметри, інтеграції)
### Крок 2: Планування структури файлів
Згрупуй пов'язаний контент за логічними темами. Кожен файл
має охоплювати ОДНУ цілісну тему. Цільові розміри файлів:
- Ідеально: 2 000–6 000 символів на файл (1–3 chunks)
- Максимум: 10 000 символів (5 chunks)
- Якщо тема більша — розбий на підтеми
Конвенція іменування: {Назва-Теми}.txt
- Описові назви з дефісами
- Без числових префіксів (порядок не важливий для RAG)
- Назва має натякати на вміст для метаданих
Приклади:
- Platform-Overview.txt
- Getting-Started.txt
- Pricing-Plans.txt
- API-Authentication.txt
- Webhook-Integration.txt
### Крок 3: Написання файлів
Для кожного файлу дотримуйся цих правил:
Правила контенту:
- Починай з чіткого заголовка теми як звичайний текст
- Пиши звичайним текстом — без Markdown, без HTML,
без JSX-компонентів
- Перетворюй таблиці на читабельні списки або пари ключ-значення
- Перетворюй покрокові інструкції на нумеровані списки
- Включай конкретні значення: числа, ліміти, ціни, опції,
значення за замовчуванням, формати, URL
- Кожен абзац або розділ має бути зрозумілим окремо
(самодостатні chunks)
- Видаляй навігаційні елементи, посилання "Далі" та
перехресні посилання без інформаційної цінності
- Зберігай мову оригіналу документації
Оптимізація для RAG:
- Виноси важливу інформацію на початок — спочатку відповідь,
потім пояснення
- Використовуй єдину термінологію в усіх файлах
- Природно повторюй ключові терміни, щоб вони з'являлися
в декількох chunks (покращує пошук)
- Для функцій з налаштуваннями: вказуй назву, тип, значення
за замовчуванням, опції та опис
- Для інтеграцій: вказуй провайдера, метод авторизації,
кроки налаштування, доступні інструменти/функції
Що виключати:
- Скріншоти та посилання на зображення
- Розмітку UI-компонентів (tabs, accordions, cards, frames)
- Посилання "Див. також" та навігаційні блоки
- Декоративний текст та маркетинговий вміст
- Дублікат контенту (не повторюй одну інформацію в різних
файлах)
### Крок 4: Створення результату
1. Створи тимчасову директорію (напр., temp-knowledge-base/)
2. Запиши всі .txt файли в неї
3. Перелічи всі файли з розмірами та описами тем
4. Надай підсумок: загальна кількість файлів і розмір
## Опціонально: Генерація сідера Workflow-агента
Якщо проект використовує Revol і тобі також потрібно створити
AI-агента з workflow для відповідей на запитання щодо цієї
документації, згенеруй Laravel database seeder, який:
1. Створює AiAgent з:
- Відповідним system prompt для підтримки документації
- LLM: gpt-4o-mini, temperature: 0.3 (точність)
- Personality: висока ясність (8-9), висока формальність (6-7),
низький гумор (2-3), мало емодзі (1-2)
2. Будує Smart Router workflow:
- Start-нода з keyword-edges до нод-експертів
- 3-6 кастомних нод "експертів", кожна для групи тем
- Кожен експерт має свій conversation_goal з описом домену
- Кожен експерт має інструменти search_documents + get_company_info
- Один fallback-edge до ноди General Assistant
- Всі експерти з'єднані з Formatter-нодою
- Voice-ноди (STT/TTS) неактивні за замовчуванням
3. Ключові слова на edges мають відповідати природній лексиці,
яку використовують користувачі при запитаннях з кожної теми
## Вхідні дані
Моя документація знаходиться тут: [ШЛЯХ АБО URL]
Назва проекту: [НАЗВА]
Опис проекту: [КОРОТКИЙ ОПИС]
Target company_id для сідера: [ID або пропустити сідер]
```
Цей промпт найкраще працює з комплексними порталами документації, документацією продуктів, довідниками API та базами знань. Згенеровані .txt файли готові для завантаження безпосередньо у File Manager Revol — просто перетягніть та натисніть **Train**.