> ## Documentation Index
> Fetch the complete documentation index at: https://revolai.mintlify.site/llms.txt
> Use this file to discover all available pages before exploring further.
# Baza wiedzy
> Trenuj swojego agenta dokumentami i treściami
## Przegląd
Baza wiedzy wykorzystuje **RAG (Retrieval-Augmented Generation)**, aby dać Twojemu agentowi dostęp do treści biznesowych. Dokumenty są dzielone na fragmenty, konwertowane na osadzenia wektorowe i przechowywane do wyszukiwania semantycznego.
Przejdź do zakładki **Baza wiedzy** w panelu agenta. Tutaj wybierasz, które dane agent będzie wykorzystywał w swoich odpowiedziach.
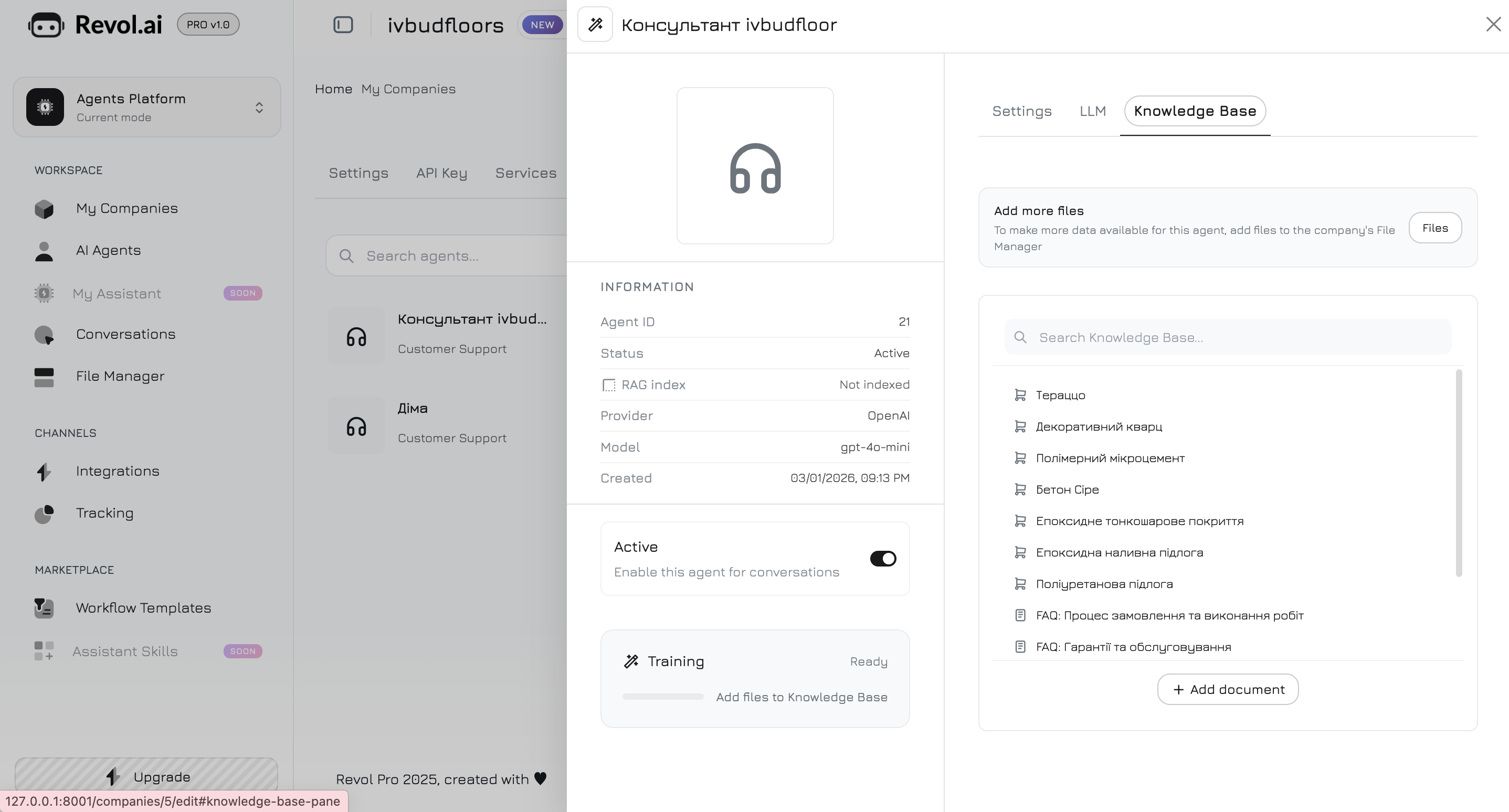
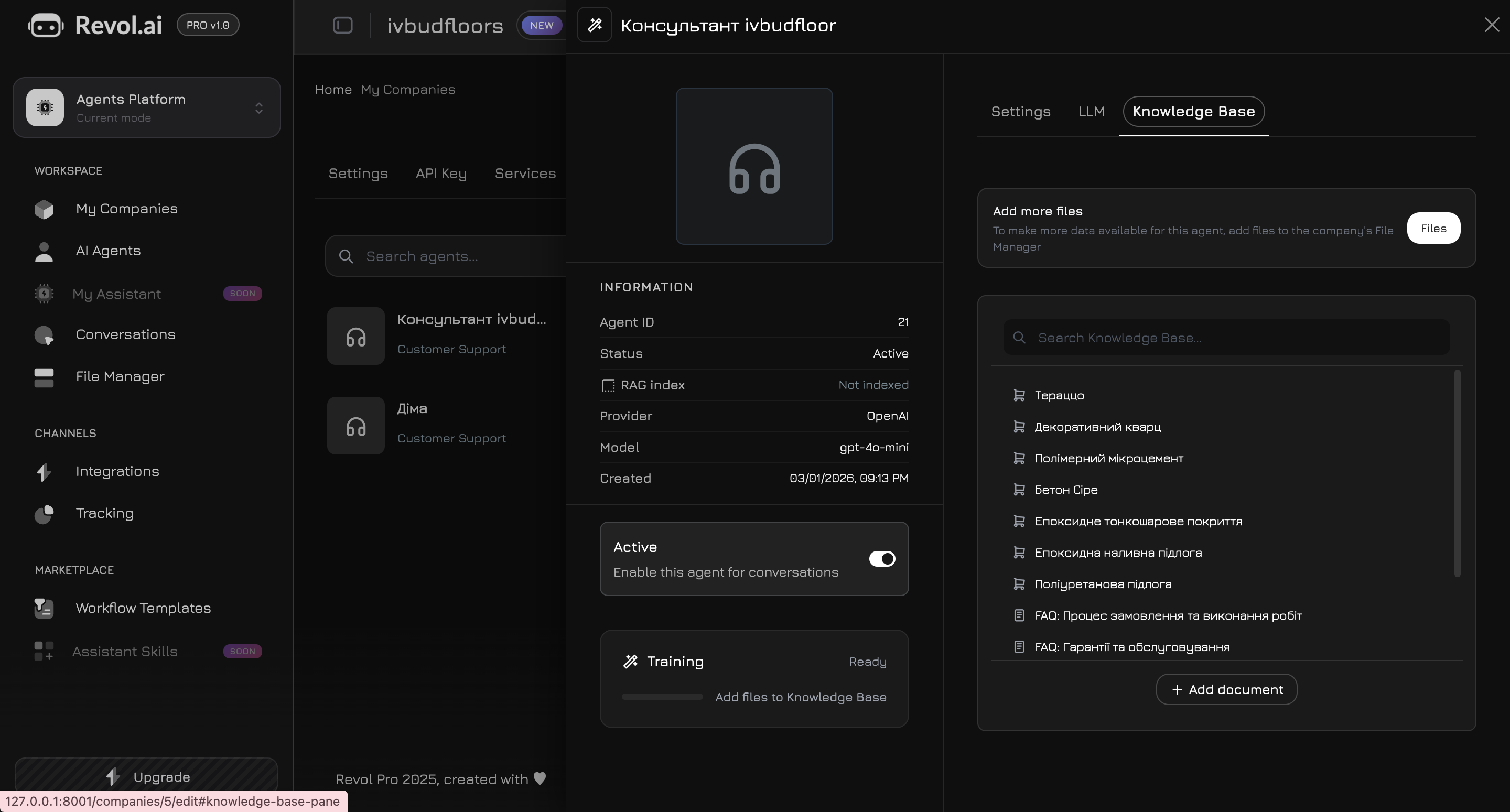 ## Dodawanie treści
### Dokumenty
Przesyłaj pliki w obsługiwanych formatach:
* PDF
* DOCX
* TXT
### Adresy URL
Podaj adresy URL stron internetowych. Revol pobierze treść i doda ją do bazy wiedzy.
### Tekst
Dodawaj treść bezpośrednio jako bloki tekstowe.
## Jak działa RAG
Przesyłasz dokument lub dodajesz treść.
Treść jest dzielona na zarządzalne fragmenty.
Każdy fragment jest konwertowany na osadzenie wektorowe za pomocą wybranego modelu embeddingu.
Osadzenia są przechowywane w PostgreSQL z rozszerzeniem pgvector.
Gdy użytkownik zadaje pytanie, najbardziej podobne fragmenty są pobierane za pomocą podobieństwa kosinusowego.
Pobrane fragmenty są wstrzykiwane do promptu LLM jako kontekst.
## Ustawienia RAG
Otwórz ustawienia RAG przez **ikonę koła zębatego** (⚙) w panelu przechowywania bazy wiedzy. Wszystkie ustawienia są per firma i zapisują się automatycznie.
### Model embeddingu
Wybierz model do konwersji tekstu na embeddingi wektorowe:
| Model | Dostawca | Wymiary | Cena | Najlepszy do |
| ---------------------- | --------- | ------- | ----------------- | ------------------------------------ |
| text-embedding-3-small | OpenAI | 1536 | \$0.02/1M tokenów | Ogólne użycie, treści angielskie |
| text-embedding-3-large | OpenAI | 1536 | \$0.13/1M tokenów | Wyższa dokładność, treści angielskie |
| BGE-M3 | DeepInfra | 1024 | \$0.01/1M tokenów | Treści wielojęzyczne (100+ języków) |
Zmiana modelu embeddingu **usuwa wszystkie istniejące embeddingi** firmy. Po zmianie musisz ponownie wytrenować wszystkich agentów. Przed zastosowaniem zmiany pojawi się okno potwierdzenia.
### Limit chunków
Ile fragmentów tekstu jest zwracanych na jedno wyszukiwanie RAG (1–20). Domyślnie: **5**.
Wyższe wartości dostarczają więcej kontekstu dla LLM, ale zwiększają zużycie tokenów.
### Limit znaków
Maksymalna liczba znaków na fragment przy dzieleniu dokumentów (500–10 000). Domyślnie: **1 500**.
Mniejsze fragmenty dają dokładniejsze wyszukiwanie. Większe zachowują więcej kontekstu w każdym wyniku.
### Nakładanie chunków
Nakładanie między kolejnymi fragmentami (0–40%). Domyślnie: **15%**.
Nakładanie zapewnia, że ważny kontekst na granicach fragmentów nie zostanie utracony. Większe nakładanie tworzy więcej chunków i zużywa więcej miejsca.
### Próg podobieństwa
Minimalne podobieństwo kosinusowe do uwzględnienia wyniku (0,1–1,0). Domyślnie: **0,35**.
Niższe wartości zwracają więcej wyników (lepszy recall). Wyższe wartości zwracają tylko wysoko trafne wyniki (lepsza precyzja). Dla treści wielojęzycznych używaj niższych progów (0,3–0,4).
## Limity przechowywania
| Plan | Dokumenty wiedzy | Tokeny osadzeń |
| ------------- | ---------------- | -------------- |
| Darmowy | 10 | 100 000 |
| Premium | 100 | 1 000 000 |
| Profesjonalny | 1 000 | 5 000 000 |
***
## Generowanie bazy wiedzy za pomocą Claude Code
Jeśli masz dokumentację projektu (strony internetowe, portal dokumentacji, pliki README, wiki) i chcesz przekształcić ją w strukturalną bazę wiedzy dla swojego agenta AI Revol, możesz użyć **Claude Code** do analizy dokumentacji i wygenerowania gotowych do przesłania plików TXT.
```text theme={null}
# Instrukcja: Generowanie plików bazy wiedzy z dokumentacji
## Kontekst
Używam Revol — platformy do tworzenia agentów sprzedaży AI
z RAG (Retrieval-Augmented Generation). Mój agent odpowiada
na pytania korzystając z bazy wiedzy: przesłane pliki są
dzielone na fragmenty (chunks, maks. 2000 znaków, 20%
nakładania się), konwertowane na wektory przez OpenAI
text-embedding-ada-002 (1536 wymiarów), przechowywane w
PostgreSQL z pgvector i przeszukiwane za pomocą podobieństwa
kosinusowego podczas inferencji.
Muszę przekształcić dokumentację mojego projektu w zestaw
plików .txt zoptymalizowanych pod ten pipeline RAG — aby
agent mógł znajdować i cytować dokładne odpowiedzi.
## Jak działa chunking RAG (ważne dla struktury plików)
- Każdy plik jest dzielony na fragmenty po ~2000 znaków
z 20% nakładaniem na granicach zdań
- Nazwa pliku staje się częścią metadanych embeddingu —
używaj opisowych nazw
- Krótsze, skoncentrowane pliki działają lepiej niż jeden duży
- Każdy chunk powinien być zrozumiały sam w sobie
- Strukturyzowana treść (listy, tabele jako tekst, jasne
nagłówki) dzieli się lepiej niż ciągły tekst
## Twoje zadanie
### Krok 1: Analiza całej dokumentacji
Przeczytaj każdy plik dokumentacji projektu. Dla każdego
pliku zidentyfikuj:
1. Temat, który obejmuje
2. Kluczowe fakty, ustawienia, konfiguracje i wartości
3. Procedury krok po kroku
4. Opisy funkcji ze szczegółami (limity, opcje, formaty)
5. Ceny, plany i limity (jeśli dotyczy)
6. Szczegóły techniczne (API, parametry, integracje)
### Krok 2: Planowanie struktury plików
Pogrupuj powiązaną treść w logiczne tematy. Każdy plik
powinien obejmować JEDEN spójny temat. Docelowe rozmiary:
- Idealnie: 2 000–6 000 znaków na plik (1–3 chunki)
- Maksymalnie: 10 000 znaków (5 chunków)
- Jeśli temat jest większy, podziel na podtematy
Konwencja nazewnictwa: {Nazwa-Tematu}.txt
- Opisowe nazwy z myślnikami
- Bez prefiksów numerycznych (kolejność nie ma znaczenia dla RAG)
- Nazwa powinna wskazywać na zawartość
Przykłady:
- Platform-Overview.txt
- Getting-Started.txt
- Pricing-Plans.txt
- API-Authentication.txt
- Webhook-Integration.txt
### Krok 3: Pisanie plików
Dla każdego pliku przestrzegaj tych zasad:
Zasady treści:
- Zacznij od jasnego nagłówka tematu jako zwykły tekst
- Pisz zwykłym tekstem — bez Markdown, bez HTML,
bez komponentów JSX
- Konwertuj tabele na czytelne listy lub pary klucz-wartość
- Konwertuj instrukcje krok po kroku na listy numerowane
- Podawaj konkretne wartości: liczby, limity, ceny, opcje,
wartości domyślne, formaty, URL
- Każdy akapit powinien być zrozumiały sam w sobie
(samodzielne chunki)
- Usuń elementy nawigacyjne i linki bez wartości informacyjnej
- Zachowaj oryginalny język dokumentacji
Optymalizacja pod RAG:
- Umieszczaj ważne informacje na początku — odpowiedź
przed wyjaśnieniem
- Używaj spójnej terminologii we wszystkich plikach
- Naturalnie powtarzaj kluczowe terminy (poprawia wyszukiwanie)
- Dla funkcji z ustawieniami: nazwa, typ, wartość domyślna,
opcje i opis
- Dla integracji: dostawca, metoda auth, kroki konfiguracji,
dostępne narzędzia/funkcje
Co wykluczyć:
- Zrzuty ekranu i odniesienia do obrazów
- Markup komponentów UI (tabs, accordions, cards, frames)
- Linki "Zobacz też" i nawigacja
- Tekst dekoracyjny i treści marketingowe
- Zduplikowana treść
### Krok 4: Utworzenie wyniku
1. Utwórz tymczasowy katalog (np. temp-knowledge-base/)
2. Zapisz wszystkie pliki .txt
3. Wylistuj pliki z rozmiarami i opisami tematów
4. Podaj podsumowanie: łączna liczba plików i rozmiar
## Opcjonalnie: Generowanie seedera agenta z workflow
Jeśli projekt używa Revol i potrzebujesz też stworzyć
agenta AI z workflow, wygeneruj Laravel database seeder, który:
1. Tworzy AiAgent z:
- Odpowiednim system promptem do wsparcia dokumentacji
- LLM: gpt-4o-mini, temperature: 0.3 (dokładność)
- Osobowość: wysoka jasność (8-9), wysoka formalność (6-7),
mało humoru (2-3), mało emoji (1-2)
2. Buduje workflow Smart Router:
- Node Start z keyword-edges do node'ów ekspertów
- 3-6 custom node'ów "ekspertów", każdy dla grupy tematycznej
- Każdy ekspert ma conversation_goal opisujący domenę
- Każdy ekspert ma narzędzia search_documents + get_company_info
- Jeden fallback-edge do node'a General Assistant
- Wszyscy eksperci połączeni z node'em Formatter
- Node'y głosowe (STT/TTS) domyślnie nieaktywne
3. Słowa kluczowe na edges powinny odpowiadać naturalnemu
słownictwu użytkowników
## Dane wejściowe
Moja dokumentacja znajduje się tu: [ŚCIEŻKA LUB URL]
Nazwa projektu: [NAZWA]
Opis projektu: [KRÓTKI OPIS]
company_id dla seedera: [ID lub pomiń seeder]
```
Ten prompt działa najlepiej z kompleksowymi portalami dokumentacji, dokumentacją produktów, referencjami API i bazami wiedzy. Wygenerowane pliki .txt są gotowe do przesłania bezpośrednio do File Managera Revol — wystarczy przeciągnąć i upuścić, a następnie kliknąć **Train**.
## Dodawanie treści
### Dokumenty
Przesyłaj pliki w obsługiwanych formatach:
* PDF
* DOCX
* TXT
### Adresy URL
Podaj adresy URL stron internetowych. Revol pobierze treść i doda ją do bazy wiedzy.
### Tekst
Dodawaj treść bezpośrednio jako bloki tekstowe.
## Jak działa RAG
Przesyłasz dokument lub dodajesz treść.
Treść jest dzielona na zarządzalne fragmenty.
Każdy fragment jest konwertowany na osadzenie wektorowe za pomocą wybranego modelu embeddingu.
Osadzenia są przechowywane w PostgreSQL z rozszerzeniem pgvector.
Gdy użytkownik zadaje pytanie, najbardziej podobne fragmenty są pobierane za pomocą podobieństwa kosinusowego.
Pobrane fragmenty są wstrzykiwane do promptu LLM jako kontekst.
## Ustawienia RAG
Otwórz ustawienia RAG przez **ikonę koła zębatego** (⚙) w panelu przechowywania bazy wiedzy. Wszystkie ustawienia są per firma i zapisują się automatycznie.
### Model embeddingu
Wybierz model do konwersji tekstu na embeddingi wektorowe:
| Model | Dostawca | Wymiary | Cena | Najlepszy do |
| ---------------------- | --------- | ------- | ----------------- | ------------------------------------ |
| text-embedding-3-small | OpenAI | 1536 | \$0.02/1M tokenów | Ogólne użycie, treści angielskie |
| text-embedding-3-large | OpenAI | 1536 | \$0.13/1M tokenów | Wyższa dokładność, treści angielskie |
| BGE-M3 | DeepInfra | 1024 | \$0.01/1M tokenów | Treści wielojęzyczne (100+ języków) |
Zmiana modelu embeddingu **usuwa wszystkie istniejące embeddingi** firmy. Po zmianie musisz ponownie wytrenować wszystkich agentów. Przed zastosowaniem zmiany pojawi się okno potwierdzenia.
### Limit chunków
Ile fragmentów tekstu jest zwracanych na jedno wyszukiwanie RAG (1–20). Domyślnie: **5**.
Wyższe wartości dostarczają więcej kontekstu dla LLM, ale zwiększają zużycie tokenów.
### Limit znaków
Maksymalna liczba znaków na fragment przy dzieleniu dokumentów (500–10 000). Domyślnie: **1 500**.
Mniejsze fragmenty dają dokładniejsze wyszukiwanie. Większe zachowują więcej kontekstu w każdym wyniku.
### Nakładanie chunków
Nakładanie między kolejnymi fragmentami (0–40%). Domyślnie: **15%**.
Nakładanie zapewnia, że ważny kontekst na granicach fragmentów nie zostanie utracony. Większe nakładanie tworzy więcej chunków i zużywa więcej miejsca.
### Próg podobieństwa
Minimalne podobieństwo kosinusowe do uwzględnienia wyniku (0,1–1,0). Domyślnie: **0,35**.
Niższe wartości zwracają więcej wyników (lepszy recall). Wyższe wartości zwracają tylko wysoko trafne wyniki (lepsza precyzja). Dla treści wielojęzycznych używaj niższych progów (0,3–0,4).
## Limity przechowywania
| Plan | Dokumenty wiedzy | Tokeny osadzeń |
| ------------- | ---------------- | -------------- |
| Darmowy | 10 | 100 000 |
| Premium | 100 | 1 000 000 |
| Profesjonalny | 1 000 | 5 000 000 |
***
## Generowanie bazy wiedzy za pomocą Claude Code
Jeśli masz dokumentację projektu (strony internetowe, portal dokumentacji, pliki README, wiki) i chcesz przekształcić ją w strukturalną bazę wiedzy dla swojego agenta AI Revol, możesz użyć **Claude Code** do analizy dokumentacji i wygenerowania gotowych do przesłania plików TXT.
```text theme={null}
# Instrukcja: Generowanie plików bazy wiedzy z dokumentacji
## Kontekst
Używam Revol — platformy do tworzenia agentów sprzedaży AI
z RAG (Retrieval-Augmented Generation). Mój agent odpowiada
na pytania korzystając z bazy wiedzy: przesłane pliki są
dzielone na fragmenty (chunks, maks. 2000 znaków, 20%
nakładania się), konwertowane na wektory przez OpenAI
text-embedding-ada-002 (1536 wymiarów), przechowywane w
PostgreSQL z pgvector i przeszukiwane za pomocą podobieństwa
kosinusowego podczas inferencji.
Muszę przekształcić dokumentację mojego projektu w zestaw
plików .txt zoptymalizowanych pod ten pipeline RAG — aby
agent mógł znajdować i cytować dokładne odpowiedzi.
## Jak działa chunking RAG (ważne dla struktury plików)
- Każdy plik jest dzielony na fragmenty po ~2000 znaków
z 20% nakładaniem na granicach zdań
- Nazwa pliku staje się częścią metadanych embeddingu —
używaj opisowych nazw
- Krótsze, skoncentrowane pliki działają lepiej niż jeden duży
- Każdy chunk powinien być zrozumiały sam w sobie
- Strukturyzowana treść (listy, tabele jako tekst, jasne
nagłówki) dzieli się lepiej niż ciągły tekst
## Twoje zadanie
### Krok 1: Analiza całej dokumentacji
Przeczytaj każdy plik dokumentacji projektu. Dla każdego
pliku zidentyfikuj:
1. Temat, który obejmuje
2. Kluczowe fakty, ustawienia, konfiguracje i wartości
3. Procedury krok po kroku
4. Opisy funkcji ze szczegółami (limity, opcje, formaty)
5. Ceny, plany i limity (jeśli dotyczy)
6. Szczegóły techniczne (API, parametry, integracje)
### Krok 2: Planowanie struktury plików
Pogrupuj powiązaną treść w logiczne tematy. Każdy plik
powinien obejmować JEDEN spójny temat. Docelowe rozmiary:
- Idealnie: 2 000–6 000 znaków na plik (1–3 chunki)
- Maksymalnie: 10 000 znaków (5 chunków)
- Jeśli temat jest większy, podziel na podtematy
Konwencja nazewnictwa: {Nazwa-Tematu}.txt
- Opisowe nazwy z myślnikami
- Bez prefiksów numerycznych (kolejność nie ma znaczenia dla RAG)
- Nazwa powinna wskazywać na zawartość
Przykłady:
- Platform-Overview.txt
- Getting-Started.txt
- Pricing-Plans.txt
- API-Authentication.txt
- Webhook-Integration.txt
### Krok 3: Pisanie plików
Dla każdego pliku przestrzegaj tych zasad:
Zasady treści:
- Zacznij od jasnego nagłówka tematu jako zwykły tekst
- Pisz zwykłym tekstem — bez Markdown, bez HTML,
bez komponentów JSX
- Konwertuj tabele na czytelne listy lub pary klucz-wartość
- Konwertuj instrukcje krok po kroku na listy numerowane
- Podawaj konkretne wartości: liczby, limity, ceny, opcje,
wartości domyślne, formaty, URL
- Każdy akapit powinien być zrozumiały sam w sobie
(samodzielne chunki)
- Usuń elementy nawigacyjne i linki bez wartości informacyjnej
- Zachowaj oryginalny język dokumentacji
Optymalizacja pod RAG:
- Umieszczaj ważne informacje na początku — odpowiedź
przed wyjaśnieniem
- Używaj spójnej terminologii we wszystkich plikach
- Naturalnie powtarzaj kluczowe terminy (poprawia wyszukiwanie)
- Dla funkcji z ustawieniami: nazwa, typ, wartość domyślna,
opcje i opis
- Dla integracji: dostawca, metoda auth, kroki konfiguracji,
dostępne narzędzia/funkcje
Co wykluczyć:
- Zrzuty ekranu i odniesienia do obrazów
- Markup komponentów UI (tabs, accordions, cards, frames)
- Linki "Zobacz też" i nawigacja
- Tekst dekoracyjny i treści marketingowe
- Zduplikowana treść
### Krok 4: Utworzenie wyniku
1. Utwórz tymczasowy katalog (np. temp-knowledge-base/)
2. Zapisz wszystkie pliki .txt
3. Wylistuj pliki z rozmiarami i opisami tematów
4. Podaj podsumowanie: łączna liczba plików i rozmiar
## Opcjonalnie: Generowanie seedera agenta z workflow
Jeśli projekt używa Revol i potrzebujesz też stworzyć
agenta AI z workflow, wygeneruj Laravel database seeder, który:
1. Tworzy AiAgent z:
- Odpowiednim system promptem do wsparcia dokumentacji
- LLM: gpt-4o-mini, temperature: 0.3 (dokładność)
- Osobowość: wysoka jasność (8-9), wysoka formalność (6-7),
mało humoru (2-3), mało emoji (1-2)
2. Buduje workflow Smart Router:
- Node Start z keyword-edges do node'ów ekspertów
- 3-6 custom node'ów "ekspertów", każdy dla grupy tematycznej
- Każdy ekspert ma conversation_goal opisujący domenę
- Każdy ekspert ma narzędzia search_documents + get_company_info
- Jeden fallback-edge do node'a General Assistant
- Wszyscy eksperci połączeni z node'em Formatter
- Node'y głosowe (STT/TTS) domyślnie nieaktywne
3. Słowa kluczowe na edges powinny odpowiadać naturalnemu
słownictwu użytkowników
## Dane wejściowe
Moja dokumentacja znajduje się tu: [ŚCIEŻKA LUB URL]
Nazwa projektu: [NAZWA]
Opis projektu: [KRÓTKI OPIS]
company_id dla seedera: [ID lub pomiń seeder]
```
Ten prompt działa najlepiej z kompleksowymi portalami dokumentacji, dokumentacją produktów, referencjami API i bazami wiedzy. Wygenerowane pliki .txt są gotowe do przesłania bezpośrednio do File Managera Revol — wystarczy przeciągnąć i upuścić, a następnie kliknąć **Train**.