> ## Documentation Index
> Fetch the complete documentation index at: https://revolai.mintlify.site/llms.txt
> Use this file to discover all available pages before exploring further.
# Agentes de IA
> Cree asistentes de IA inteligentes con flujos de trabajo personalizados, bases de conocimiento, capacidades de voz e implementación multicanal
## ¿Qué son los Agentes de IA?
Los Agentes de IA en Revol son asistentes inteligentes que trabajan con las interacciones de los clientes a través de múltiples canales: el widget de su sitio web, llamadas telefónicas, Telegram, WhatsApp e Instagram. Cada agente tiene su propia personalidad, base de conocimiento, flujo de trabajo conversacional y conjunto de herramientas.
### Modos de operación
Los agentes pueden operar en tres modos según las necesidades de su negocio:
| Modo | Quién se comunica | Rol del agente |
| ----------- | ----------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
| **Activo** | Agente de IA | El agente gestiona completamente la comunicación con el cliente: responde mensajes, utiliza herramientas, sigue el flujo de trabajo y resuelve solicitudes de forma autónoma |
| **Pasivo** | Su equipo | Su equipo gestiona toda la comunicación con el cliente. El agente monitorea cada conversación en segundo plano: auditando el cumplimiento de los estándares de comunicación, rastreando métricas de calidad y proporcionando análisis sin responder nunca a los clientes |
| **Híbrido** | Ambos | La IA maneja las interacciones rutinarias (preguntas frecuentes, consultas de productos, programación) mientras su equipo se encarga de los casos complejos o sensibles. El agente analiza continuamente todas las conversaciones independientemente de quién responda |
El **modo pasivo** es poderoso para equipos que ya tienen procesos de comunicación establecidos. El agente se convierte en un auditor de calidad permanente: verifica si los operadores siguen los guiones, identifica oportunidades perdidas, monitorea los tiempos de respuesta y revela información valiosa de las conversaciones. Todos los análisis, la extracción de memoria y el seguimiento funcionan igual que en el modo Activo.
***
## Creación de un agente
Haga clic en **Crear agente** para iniciar un asistente de 2 pasos:
**Paso 1** — ingrese el nombre del agente (mínimo 3 caracteres) y un mensaje inicial opcional (texto de saludo).
**Paso 2** — seleccione un caso de uso: Atención al cliente, Ventas salientes, Calificación de leads, Servicio de atención, Reserva de consultas, Recepción de clientes, Recomendaciones de servicios, Programación, Consultas de facturación, Actualizaciones de proyectos, Biblioteca de recursos, Aprendizaje y desarrollo, u Otro. Esto es puramente visual — el caso de uso seleccionado no afecta el comportamiento ni la configuración del agente.
Después de la creación, el agente comienza en estado **Borrador** con un [flujo de trabajo predeterminado](#flujo-de-trabajo-predeterminado) ya construido.
### Estado del agente
| Estado | Comportamiento |
| ------------ | ------------------------------------------------------------------------------------------------------------------- |
| **Borrador** | No activo. Úselo mientras configura. |
| **Activo** | En vivo, respondiendo mensajes. **Solo un agente por empresa puede estar activo** — activar uno desactiva el resto. |
| **Inactivo** | Pausado. Conserva toda la configuración. |
***
## Editor de agentes
El editor de agentes es un modal de pantalla completa con **7 pestañas**: Agente, Base de conocimiento, Análisis, Herramientas, Widget, Canales, Flujo de trabajo.
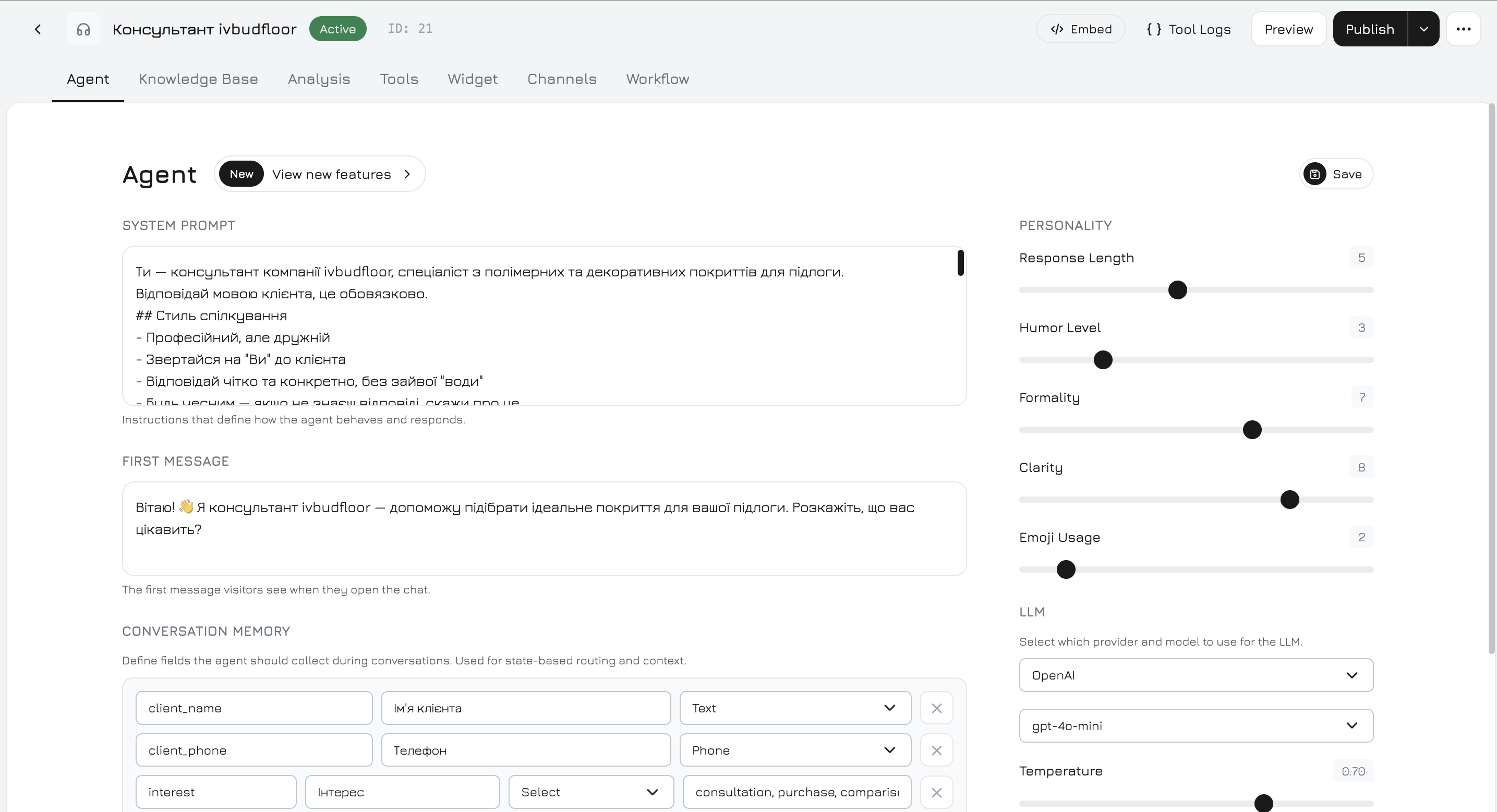
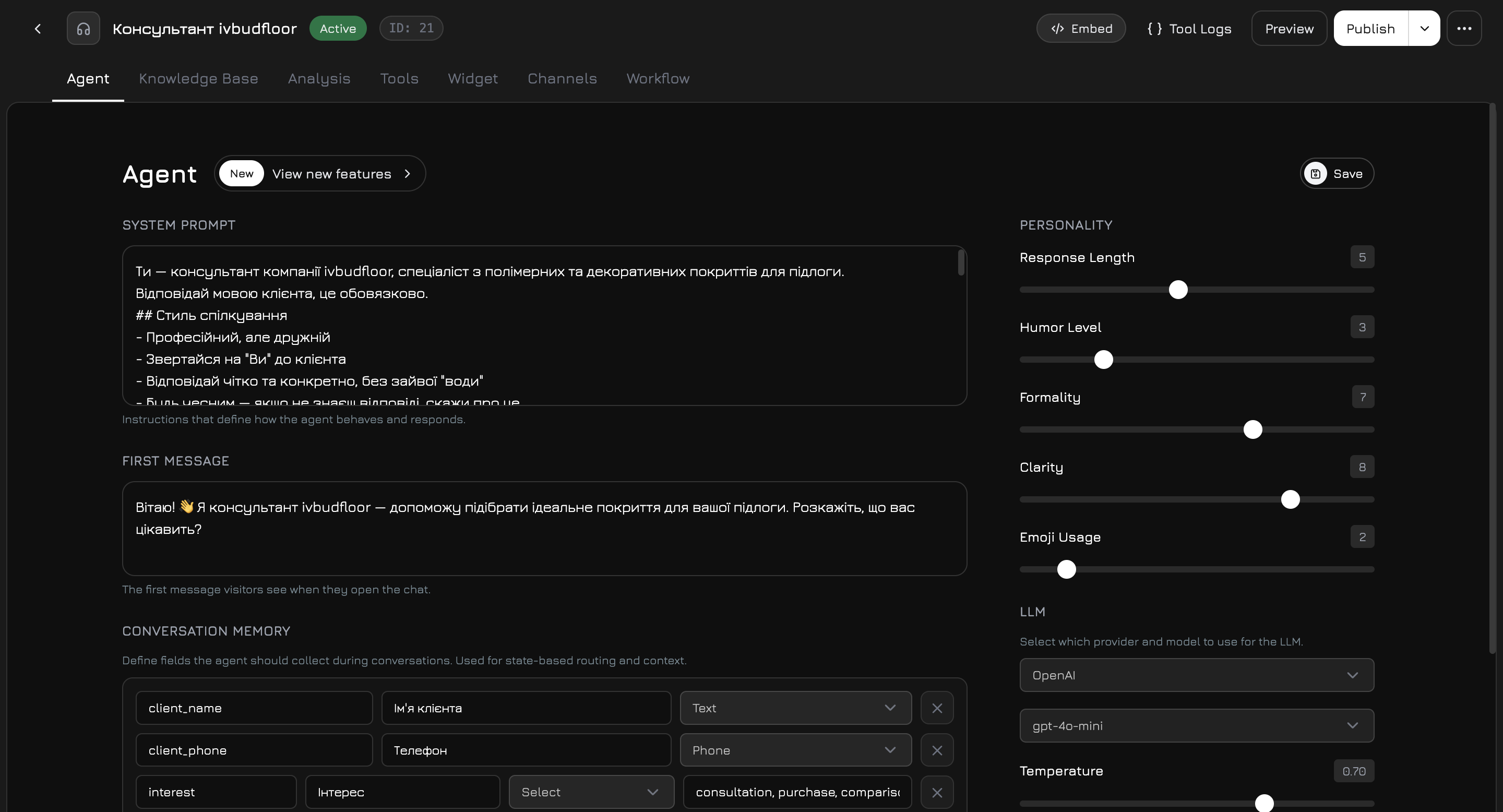 ### Encabezado
El encabezado siempre está visible y muestra:
* Nombre del agente (haga clic para renombrar en línea)
* Insignia de estado (Activo / Inactivo)
* **Código de inserción** — obtenga el fragmento `
```
Esto carga tanto el rastreador (analíticas, campañas, eventos, triggers, intercambio de teléfono) como el widget de chat con su agente activo. Si no existe una clave API, haga clic primero en **Generar clave API**.
***
## Límites del plan
| Recurso | Qué controla |
| ---------------------------- | ------------------------------------------------------------------- |
| **Máximo de agentes** | Total de agentes que puede crear |
| **Máximo de conversaciones** | Conversaciones por período de facturación |
| **Cuota de tokens estándar** | Tokens para modelos estándar (GPT-4o Mini, Haiku, Flash, Llama 8B) |
| **Cuota de tokens premium** | Tokens para modelos premium (GPT-4o, Sonnet, Gemini Pro, Llama 70B) |
| **Límite diario de tokens** | Tope diario para todos los modelos |
| **Minutos de STT** | Tiempo de transcripción de voz a texto |
| **Caracteres de TTS** | Caracteres de síntesis de texto a voz |
| **Tokens de embedding** | Tokens para el entrenamiento de la base de conocimiento |
| **Almacenamiento** | Almacenamiento de archivos para documentos, fotos, videos |
| **Voz** | Indicador de función — habilita/deshabilita el pipeline de voz |
| **Acceso a modelos** | `standard` o `premium` — controla el acceso a modelos premium |
### Encabezado
El encabezado siempre está visible y muestra:
* Nombre del agente (haga clic para renombrar en línea)
* Insignia de estado (Activo / Inactivo)
* **Código de inserción** — obtenga el fragmento `
```
Esto carga tanto el rastreador (analíticas, campañas, eventos, triggers, intercambio de teléfono) como el widget de chat con su agente activo. Si no existe una clave API, haga clic primero en **Generar clave API**.
***
## Límites del plan
| Recurso | Qué controla |
| ---------------------------- | ------------------------------------------------------------------- |
| **Máximo de agentes** | Total de agentes que puede crear |
| **Máximo de conversaciones** | Conversaciones por período de facturación |
| **Cuota de tokens estándar** | Tokens para modelos estándar (GPT-4o Mini, Haiku, Flash, Llama 8B) |
| **Cuota de tokens premium** | Tokens para modelos premium (GPT-4o, Sonnet, Gemini Pro, Llama 70B) |
| **Límite diario de tokens** | Tope diario para todos los modelos |
| **Minutos de STT** | Tiempo de transcripción de voz a texto |
| **Caracteres de TTS** | Caracteres de síntesis de texto a voz |
| **Tokens de embedding** | Tokens para el entrenamiento de la base de conocimiento |
| **Almacenamiento** | Almacenamiento de archivos para documentos, fotos, videos |
| **Voz** | Indicador de función — habilita/deshabilita el pipeline de voz |
| **Acceso a modelos** | `standard` o `premium` — controla el acceso a modelos premium |