> ## Documentation Index
> Fetch the complete documentation index at: https://revolai.mintlify.site/llms.txt
> Use this file to discover all available pages before exploring further.
# Base de conocimiento
> Entrene a su agente con documentos y contenido
## Descripción general
La Base de conocimiento utiliza **RAG (Generación Aumentada por Recuperación)** para dar a su agente acceso al contenido de su negocio. Los documentos se dividen en segmentos, se convierten en embeddings vectoriales y se almacenan para la búsqueda semántica.
Navegue a la pestaña **Base de conocimiento** en el panel del agente. Aquí usted elige qué datos utilizará el agente para sus respuestas.
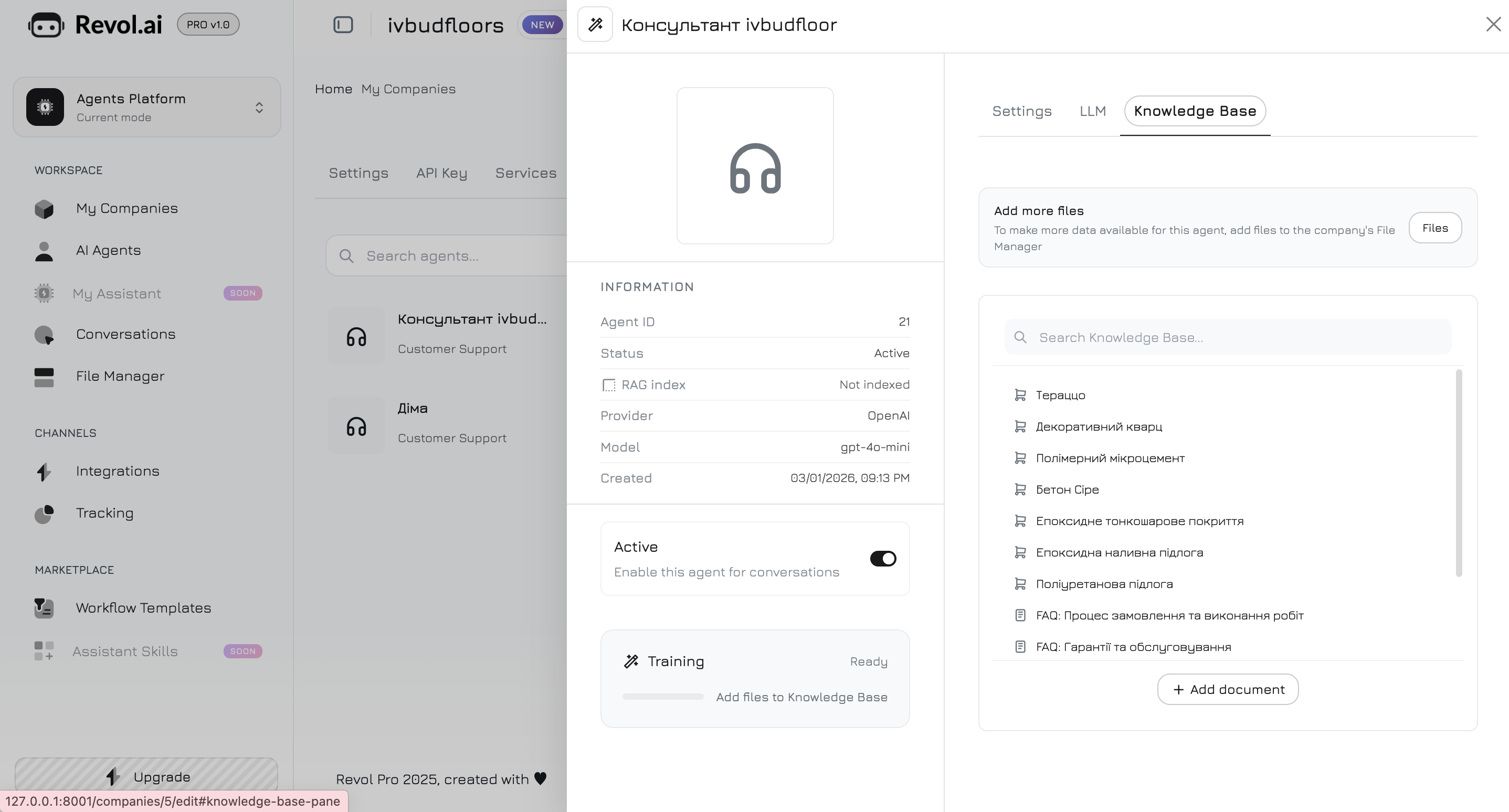
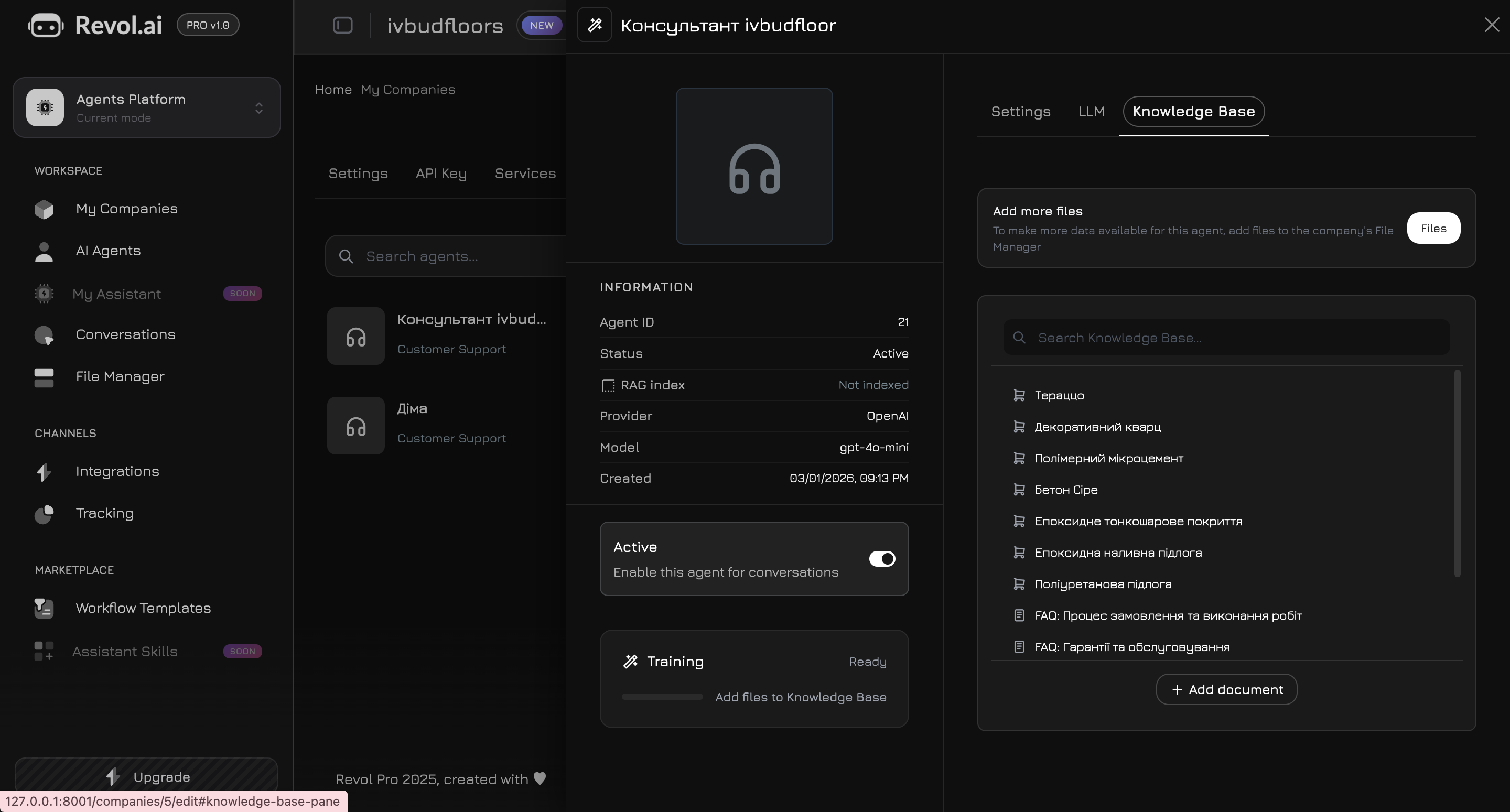 ## Agregar contenido
### Documentos
Suba archivos en formatos compatibles:
* PDF
* DOCX
* TXT
### URLs
Proporcione URLs de páginas web. Revol extraerá el contenido y lo agregará a la base de conocimiento.
### Texto
Agregue contenido directamente como bloques de texto.
## Cómo funciona RAG
Usted sube un documento o agrega contenido.
El contenido se divide en segmentos manejables.
Cada segmento se convierte en un embedding vectorial utilizando el modelo de embedding seleccionado.
Los embeddings se almacenan en PostgreSQL con la extensión pgvector.
Cuando un usuario hace una pregunta, se recuperan los segmentos más similares utilizando similitud del coseno.
Los segmentos recuperados se inyectan en el prompt del LLM como contexto.
## Configuración de RAG
Abra la configuración de RAG a través del **icono de engranaje** (⚙) en el panel de almacenamiento de la base de conocimientos. Todas las configuraciones son por empresa y se guardan automáticamente.
### Modelo de embedding
Elija qué modelo convierte su texto en embeddings vectoriales:
| Modelo | Proveedor | Dimensiones | Precio | Ideal para |
| ---------------------- | --------- | ----------- | ---------------- | ------------------------------------ |
| text-embedding-3-small | OpenAI | 1536 | \$0.02/1M tokens | Uso general, contenido en inglés |
| text-embedding-3-large | OpenAI | 1536 | \$0.13/1M tokens | Mayor precisión, contenido en inglés |
| BGE-M3 | DeepInfra | 1024 | \$0.01/1M tokens | Contenido multilingüe (100+ idiomas) |
Cambiar el modelo de embedding **elimina todos los embeddings existentes** de la empresa. Debe reentrenar todos los agentes después del cambio. Aparecerá un diálogo de confirmación antes de aplicar el cambio.
### Límite de chunks
Cuántos fragmentos de texto se devuelven por búsqueda RAG (1–20). Predeterminado: **5**.
Valores más altos proporcionan más contexto al LLM pero aumentan el uso de tokens.
### Límite de caracteres
Máximo de caracteres por fragmento al dividir documentos (500–10.000). Predeterminado: **1.500**.
Fragmentos más pequeños dan una recuperación más precisa. Más grandes preservan más contexto por resultado.
### Superposición de chunks
Superposición entre fragmentos consecutivos (0–40%). Predeterminado: **15%**.
La superposición asegura que el contexto importante en los límites de los fragmentos no se pierda. Mayor superposición crea más chunks y usa más almacenamiento.
### Umbral de similitud
Puntuación mínima de similitud coseno para incluir un resultado (0,1–1,0). Predeterminado: **0,35**.
Valores más bajos devuelven más resultados (mejor recall). Valores más altos devuelven solo resultados altamente relevantes (mejor precisión). Para contenido multilingüe, use umbrales más bajos (0,3–0,4).
## Límites de almacenamiento
| Plan | Documentos de conocimiento | Tokens de embedding |
| ----------- | -------------------------- | ------------------- |
| Gratuito | 10 | 100,000 |
| Premium | 100 | 1,000,000 |
| Profesional | 1,000 | 5,000,000 |
***
## Generar base de conocimiento con Claude Code
Si tiene documentación del proyecto (páginas web, portal de documentación, archivos README, wiki) y desea convertirla en una base de conocimiento estructurada para su agente de IA de Revol, puede usar **Claude Code** para analizar la documentación y generar archivos TXT listos para subir.
```text theme={null}
# Instrucción: Generar archivos de base de conocimiento desde documentación
## Contexto
Uso Revol — una plataforma para crear agentes de ventas con IA
y RAG (Retrieval-Augmented Generation). Mi agente responde
preguntas usando una base de conocimiento: los archivos subidos
se dividen en fragmentos (chunks, máx. 2000 caracteres, 20%
de superposición), se convierten en vectores mediante OpenAI
text-embedding-ada-002 (1536 dimensiones), se almacenan en
PostgreSQL con pgvector y se buscan por similitud coseno
durante la inferencia.
Necesito convertir la documentación de mi proyecto en un
conjunto de archivos .txt optimizados para este pipeline RAG —
para que el agente pueda encontrar y citar respuestas precisas.
## Cómo funciona el chunking de RAG (importante para la estructura)
- Cada archivo se divide en chunks de ~2000 caracteres con
20% de superposición en los límites de oraciones
- El nombre del archivo se convierte en metadatos del embedding —
usa nombres descriptivos
- Los archivos cortos y enfocados funcionan mejor que uno grande
- Cada chunk debe ser autónomo — un lector debe entenderlo
sin necesitar el texto circundante
- El contenido estructurado (listas, tablas como texto,
encabezados claros) se divide mejor que los párrafos largos
## Tu tarea
### Paso 1: Analizar toda la documentación
Lee cada archivo de documentación del proyecto. Para cada
archivo, identifica:
1. El tema que cubre
2. Datos clave, configuraciones y valores
3. Procedimientos paso a paso
4. Descripciones de funciones con detalles (límites, opciones, formatos)
5. Precios, planes y cuotas (si aplica)
6. Detalles técnicos (APIs, parámetros, integraciones)
### Paso 2: Planificar la estructura de archivos
Agrupa contenido relacionado en temas lógicos. Cada archivo
debe cubrir UN tema coherente. Tamaños objetivo:
- Ideal: 2.000–6.000 caracteres por archivo (1–3 chunks)
- Máximo: 10.000 caracteres (5 chunks)
- Si un tema es más grande, divídelo en subtemas
Convención de nombres: {Nombre-Tema}.txt
- Nombres descriptivos con guiones
- Sin prefijos numéricos (el orden no importa para RAG)
- El nombre debe indicar el contenido
Ejemplos:
- Platform-Overview.txt
- Getting-Started.txt
- Pricing-Plans.txt
- API-Authentication.txt
- Webhook-Integration.txt
### Paso 3: Escribir los archivos
Para cada archivo, sigue estas reglas:
Reglas de contenido:
- Comienza con un encabezado claro del tema en texto plano
- Escribe en texto plano — sin Markdown, sin HTML,
sin componentes JSX
- Convierte tablas en listas legibles o pares clave-valor
- Convierte guías paso a paso en listas numeradas
- Incluye valores específicos: números, límites, precios,
opciones, valores predeterminados, formatos, URLs
- Cada párrafo debe ser comprensible por sí solo
(chunks autónomos)
- Elimina elementos de navegación y enlaces sin valor
informativo
- Mantén el idioma original de la documentación
Optimización para RAG:
- Coloca la información importante primero — respuesta
antes de explicación
- Usa terminología consistente en todos los archivos
- Repite términos clave naturalmente (mejora la búsqueda)
- Para funciones con configuración: nombre, tipo, valor
predeterminado, opciones y descripción
- Para integraciones: proveedor, método de auth, pasos
de configuración, herramientas disponibles
Qué excluir:
- Capturas de pantalla y referencias a imágenes
- Markup de componentes UI (tabs, accordions, cards, frames)
- Enlaces "Ver también" y navegación
- Texto decorativo y contenido de marketing
- Contenido duplicado
### Paso 4: Crear la salida
1. Crea un directorio temporal (ej., temp-knowledge-base/)
2. Escribe todos los archivos .txt en él
3. Lista todos los archivos con tamaños y descripciones
4. Proporciona un resumen: total de archivos y tamaño
## Opcional: Generar un Seeder de Agente con Workflow
Si el proyecto usa Revol y también necesitas crear un agente
de IA con workflow, genera un Laravel database seeder que:
1. Cree un AiAgent con:
- System prompt apropiado para soporte de documentación
- LLM: gpt-4o-mini, temperature: 0.3 (precisión)
- Personalidad: alta claridad (8-9), alta formalidad (6-7),
poco humor (2-3), pocos emojis (1-2)
2. Construya un workflow Smart Router:
- Nodo Start con edges basados en keywords hacia nodos expertos
- 3-6 nodos custom "expertos", cada uno para un grupo temático
- Cada experto con su conversation_goal describiendo su dominio
- Cada experto con herramientas search_documents + get_company_info
- Un edge fallback hacia un nodo General Assistant
- Todos los expertos conectados a un nodo Formatter
- Nodos de voz (STT/TTS) inactivos por defecto
3. Las keywords en los edges deben coincidir con el vocabulario
natural que usan los usuarios
## Entrada
Mi documentación está en: [RUTA O URL]
Nombre del proyecto: [NOMBRE]
Descripción del proyecto: [DESCRIPCIÓN BREVE]
company_id para el seeder: [ID o saltar seeder]
```
Este prompt funciona mejor con portales de documentación completos, documentación de productos, referencias de API y bases de conocimiento. Los archivos .txt generados están listos para subir directamente al File Manager de Revol — solo arrastre y suelte, luego haga clic en **Train**.
## Agregar contenido
### Documentos
Suba archivos en formatos compatibles:
* PDF
* DOCX
* TXT
### URLs
Proporcione URLs de páginas web. Revol extraerá el contenido y lo agregará a la base de conocimiento.
### Texto
Agregue contenido directamente como bloques de texto.
## Cómo funciona RAG
Usted sube un documento o agrega contenido.
El contenido se divide en segmentos manejables.
Cada segmento se convierte en un embedding vectorial utilizando el modelo de embedding seleccionado.
Los embeddings se almacenan en PostgreSQL con la extensión pgvector.
Cuando un usuario hace una pregunta, se recuperan los segmentos más similares utilizando similitud del coseno.
Los segmentos recuperados se inyectan en el prompt del LLM como contexto.
## Configuración de RAG
Abra la configuración de RAG a través del **icono de engranaje** (⚙) en el panel de almacenamiento de la base de conocimientos. Todas las configuraciones son por empresa y se guardan automáticamente.
### Modelo de embedding
Elija qué modelo convierte su texto en embeddings vectoriales:
| Modelo | Proveedor | Dimensiones | Precio | Ideal para |
| ---------------------- | --------- | ----------- | ---------------- | ------------------------------------ |
| text-embedding-3-small | OpenAI | 1536 | \$0.02/1M tokens | Uso general, contenido en inglés |
| text-embedding-3-large | OpenAI | 1536 | \$0.13/1M tokens | Mayor precisión, contenido en inglés |
| BGE-M3 | DeepInfra | 1024 | \$0.01/1M tokens | Contenido multilingüe (100+ idiomas) |
Cambiar el modelo de embedding **elimina todos los embeddings existentes** de la empresa. Debe reentrenar todos los agentes después del cambio. Aparecerá un diálogo de confirmación antes de aplicar el cambio.
### Límite de chunks
Cuántos fragmentos de texto se devuelven por búsqueda RAG (1–20). Predeterminado: **5**.
Valores más altos proporcionan más contexto al LLM pero aumentan el uso de tokens.
### Límite de caracteres
Máximo de caracteres por fragmento al dividir documentos (500–10.000). Predeterminado: **1.500**.
Fragmentos más pequeños dan una recuperación más precisa. Más grandes preservan más contexto por resultado.
### Superposición de chunks
Superposición entre fragmentos consecutivos (0–40%). Predeterminado: **15%**.
La superposición asegura que el contexto importante en los límites de los fragmentos no se pierda. Mayor superposición crea más chunks y usa más almacenamiento.
### Umbral de similitud
Puntuación mínima de similitud coseno para incluir un resultado (0,1–1,0). Predeterminado: **0,35**.
Valores más bajos devuelven más resultados (mejor recall). Valores más altos devuelven solo resultados altamente relevantes (mejor precisión). Para contenido multilingüe, use umbrales más bajos (0,3–0,4).
## Límites de almacenamiento
| Plan | Documentos de conocimiento | Tokens de embedding |
| ----------- | -------------------------- | ------------------- |
| Gratuito | 10 | 100,000 |
| Premium | 100 | 1,000,000 |
| Profesional | 1,000 | 5,000,000 |
***
## Generar base de conocimiento con Claude Code
Si tiene documentación del proyecto (páginas web, portal de documentación, archivos README, wiki) y desea convertirla en una base de conocimiento estructurada para su agente de IA de Revol, puede usar **Claude Code** para analizar la documentación y generar archivos TXT listos para subir.
```text theme={null}
# Instrucción: Generar archivos de base de conocimiento desde documentación
## Contexto
Uso Revol — una plataforma para crear agentes de ventas con IA
y RAG (Retrieval-Augmented Generation). Mi agente responde
preguntas usando una base de conocimiento: los archivos subidos
se dividen en fragmentos (chunks, máx. 2000 caracteres, 20%
de superposición), se convierten en vectores mediante OpenAI
text-embedding-ada-002 (1536 dimensiones), se almacenan en
PostgreSQL con pgvector y se buscan por similitud coseno
durante la inferencia.
Necesito convertir la documentación de mi proyecto en un
conjunto de archivos .txt optimizados para este pipeline RAG —
para que el agente pueda encontrar y citar respuestas precisas.
## Cómo funciona el chunking de RAG (importante para la estructura)
- Cada archivo se divide en chunks de ~2000 caracteres con
20% de superposición en los límites de oraciones
- El nombre del archivo se convierte en metadatos del embedding —
usa nombres descriptivos
- Los archivos cortos y enfocados funcionan mejor que uno grande
- Cada chunk debe ser autónomo — un lector debe entenderlo
sin necesitar el texto circundante
- El contenido estructurado (listas, tablas como texto,
encabezados claros) se divide mejor que los párrafos largos
## Tu tarea
### Paso 1: Analizar toda la documentación
Lee cada archivo de documentación del proyecto. Para cada
archivo, identifica:
1. El tema que cubre
2. Datos clave, configuraciones y valores
3. Procedimientos paso a paso
4. Descripciones de funciones con detalles (límites, opciones, formatos)
5. Precios, planes y cuotas (si aplica)
6. Detalles técnicos (APIs, parámetros, integraciones)
### Paso 2: Planificar la estructura de archivos
Agrupa contenido relacionado en temas lógicos. Cada archivo
debe cubrir UN tema coherente. Tamaños objetivo:
- Ideal: 2.000–6.000 caracteres por archivo (1–3 chunks)
- Máximo: 10.000 caracteres (5 chunks)
- Si un tema es más grande, divídelo en subtemas
Convención de nombres: {Nombre-Tema}.txt
- Nombres descriptivos con guiones
- Sin prefijos numéricos (el orden no importa para RAG)
- El nombre debe indicar el contenido
Ejemplos:
- Platform-Overview.txt
- Getting-Started.txt
- Pricing-Plans.txt
- API-Authentication.txt
- Webhook-Integration.txt
### Paso 3: Escribir los archivos
Para cada archivo, sigue estas reglas:
Reglas de contenido:
- Comienza con un encabezado claro del tema en texto plano
- Escribe en texto plano — sin Markdown, sin HTML,
sin componentes JSX
- Convierte tablas en listas legibles o pares clave-valor
- Convierte guías paso a paso en listas numeradas
- Incluye valores específicos: números, límites, precios,
opciones, valores predeterminados, formatos, URLs
- Cada párrafo debe ser comprensible por sí solo
(chunks autónomos)
- Elimina elementos de navegación y enlaces sin valor
informativo
- Mantén el idioma original de la documentación
Optimización para RAG:
- Coloca la información importante primero — respuesta
antes de explicación
- Usa terminología consistente en todos los archivos
- Repite términos clave naturalmente (mejora la búsqueda)
- Para funciones con configuración: nombre, tipo, valor
predeterminado, opciones y descripción
- Para integraciones: proveedor, método de auth, pasos
de configuración, herramientas disponibles
Qué excluir:
- Capturas de pantalla y referencias a imágenes
- Markup de componentes UI (tabs, accordions, cards, frames)
- Enlaces "Ver también" y navegación
- Texto decorativo y contenido de marketing
- Contenido duplicado
### Paso 4: Crear la salida
1. Crea un directorio temporal (ej., temp-knowledge-base/)
2. Escribe todos los archivos .txt en él
3. Lista todos los archivos con tamaños y descripciones
4. Proporciona un resumen: total de archivos y tamaño
## Opcional: Generar un Seeder de Agente con Workflow
Si el proyecto usa Revol y también necesitas crear un agente
de IA con workflow, genera un Laravel database seeder que:
1. Cree un AiAgent con:
- System prompt apropiado para soporte de documentación
- LLM: gpt-4o-mini, temperature: 0.3 (precisión)
- Personalidad: alta claridad (8-9), alta formalidad (6-7),
poco humor (2-3), pocos emojis (1-2)
2. Construya un workflow Smart Router:
- Nodo Start con edges basados en keywords hacia nodos expertos
- 3-6 nodos custom "expertos", cada uno para un grupo temático
- Cada experto con su conversation_goal describiendo su dominio
- Cada experto con herramientas search_documents + get_company_info
- Un edge fallback hacia un nodo General Assistant
- Todos los expertos conectados a un nodo Formatter
- Nodos de voz (STT/TTS) inactivos por defecto
3. Las keywords en los edges deben coincidir con el vocabulario
natural que usan los usuarios
## Entrada
Mi documentación está en: [RUTA O URL]
Nombre del proyecto: [NOMBRE]
Descripción del proyecto: [DESCRIPCIÓN BREVE]
company_id para el seeder: [ID o saltar seeder]
```
Este prompt funciona mejor con portales de documentación completos, documentación de productos, referencias de API y bases de conocimiento. Los archivos .txt generados están listos para subir directamente al File Manager de Revol — solo arrastre y suelte, luego haga clic en **Train**.