> ## Documentation Index
> Fetch the complete documentation index at: https://revolai.mintlify.site/llms.txt
> Use this file to discover all available pages before exploring further.
# Wissensdatenbank
> Trainieren Sie Ihren Agenten mit Dokumenten und Inhalten
## Überblick
Die Wissensdatenbank verwendet **RAG (Retrieval-Augmented Generation)**, um Ihrem Agenten Zugang zu Ihren Geschäftsinhalten zu geben. Dokumente werden in Chunks aufgeteilt, in Vektor-Embeddings umgewandelt und für die semantische Suche gespeichert.
Navigieren Sie zum Tab **Wissensdatenbank** im Agenten-Panel. Hier wählen Sie aus, welche Daten der Agent für seine Antworten verwenden soll.
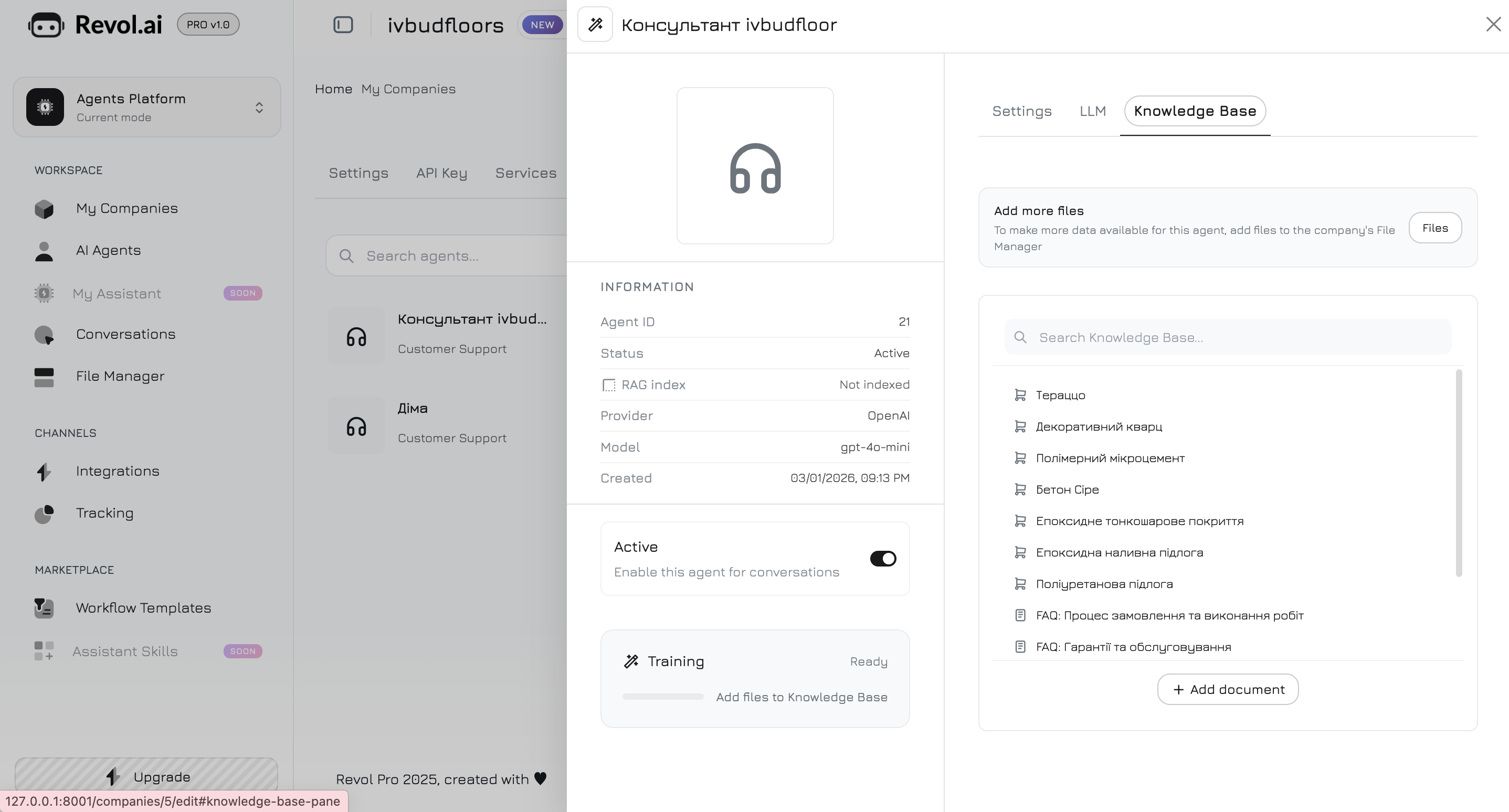
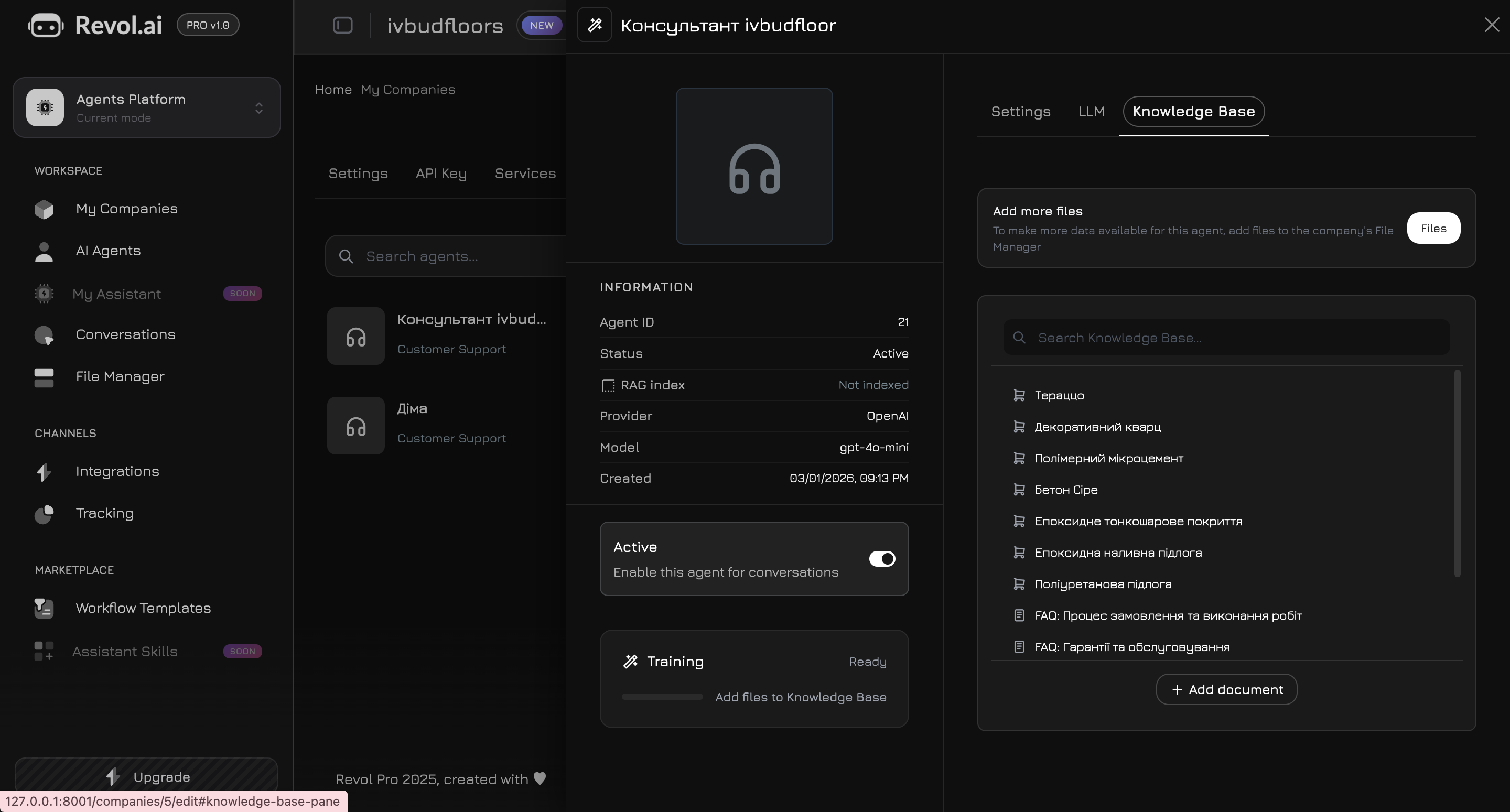 ## Inhalte hinzufügen
### Dokumente
Laden Sie Dateien in unterstützten Formaten hoch:
* PDF
* DOCX
* TXT
### URLs
Geben Sie Webseiten-URLs an. Revol wird den Inhalt extrahieren und zur Wissensdatenbank hinzufügen.
### Text
Fügen Sie Inhalte direkt als Textblöcke hinzu.
## Wie RAG funktioniert
Sie laden ein Dokument hoch oder fügen Inhalte hinzu.
Der Inhalt wird in handhabbare Chunks aufgeteilt.
Jeder Chunk wird mithilfe des ausgewählten Embedding-Modells in ein Vektor-Embedding umgewandelt.
Embeddings werden in PostgreSQL mit der pgvector-Erweiterung gespeichert.
Wenn ein Benutzer eine Frage stellt, werden die ähnlichsten Chunks mittels Kosinusähnlichkeit abgerufen.
Abgerufene Chunks werden als Kontext in den LLM-Prompt injiziert.
## RAG-Einstellungen
Öffnen Sie die RAG-Einstellungen über das **Zahnrad-Symbol** (⚙) im Speicherpanel der Wissensdatenbank. Alle Einstellungen gelten pro Unternehmen und werden automatisch gespeichert.
### Embedding-Modell
Wählen Sie das Modell zur Umwandlung Ihres Textes in Vektor-Embeddings:
| Modell | Anbieter | Dimensionen | Preis | Ideal für |
| ---------------------- | --------- | ----------- | --------------- | ------------------------------------- |
| text-embedding-3-small | OpenAI | 1536 | \$0.02/1M Token | Allgemeine Nutzung, englischer Inhalt |
| text-embedding-3-large | OpenAI | 1536 | \$0.13/1M Token | Höhere Genauigkeit, englischer Inhalt |
| BGE-M3 | DeepInfra | 1024 | \$0.01/1M Token | Mehrsprachiger Inhalt (100+ Sprachen) |
Das Ändern des Embedding-Modells **löscht alle bestehenden Embeddings** des Unternehmens. Nach dem Wechsel müssen alle Agenten neu trainiert werden. Vor der Änderung erscheint ein Bestätigungsdialog.
### Chunk-Limit
Wie viele Textfragmente pro RAG-Suche zurückgegeben werden (1–20). Standard: **5**.
Höhere Werte liefern mehr Kontext für das LLM, erhöhen aber den Token-Verbrauch.
### Zeichenlimit
Maximale Zeichen pro Fragment beim Aufteilen von Dokumenten (500–10.000). Standard: **1.500**.
Kleinere Fragmente ermöglichen präziseres Retrieval. Größere bewahren mehr Kontext pro Ergebnis.
### Chunk-Überlappung
Überlappung zwischen aufeinanderfolgenden Fragmenten (0–40%). Standard: **15%**.
Überlappung stellt sicher, dass wichtiger Kontext an Fragment-Grenzen nicht verloren geht. Mehr Überlappung erzeugt mehr Chunks und verbraucht mehr Speicher.
### Ähnlichkeitsschwelle
Minimale Kosinus-Ähnlichkeit für ein Ergebnis (0,1–1,0). Standard: **0,35**.
Niedrigere Werte liefern mehr Ergebnisse (besserer Recall). Höhere Werte liefern nur hochrelevante Ergebnisse (bessere Präzision). Für mehrsprachige Inhalte verwenden Sie niedrigere Schwellen (0,3–0,4).
## Speicherlimits
| Plan | Wissensdokumente | Embedding-Tokens |
| ------------ | ---------------- | ---------------- |
| Free | 10 | 100.000 |
| Premium | 100 | 1.000.000 |
| Professional | 1.000 | 5.000.000 |
***
## Wissensdatenbank mit Claude Code generieren
Wenn Sie Projektdokumentation haben (Website-Seiten, Dokumentationsportal, README-Dateien, Wiki) und diese in eine strukturierte Wissensdatenbank für Ihren Revol AI-Agenten umwandeln möchten, können Sie **Claude Code** verwenden, um die Dokumentation zu analysieren und uploadfertige TXT-Dateien zu generieren.
```text theme={null}
# Anleitung: Wissensdatenbank-Dateien aus Dokumentation generieren
## Kontext
Ich verwende Revol — eine Plattform zur Erstellung von
AI-Vertriebsagenten mit RAG (Retrieval-Augmented Generation).
Mein Agent beantwortet Fragen mithilfe einer Wissensdatenbank:
Hochgeladene Dateien werden in Chunks aufgeteilt (max. 2000
Zeichen, 20% Überlappung), über OpenAI text-embedding-ada-002
(1536 Dimensionen) eingebettet, in PostgreSQL mit pgvector
gespeichert und zur Inferenzzeit per Kosinus-Ähnlichkeit
durchsucht.
Ich muss meine Projektdokumentation in eine Reihe von
.txt-Dateien umwandeln, die für diese RAG-Pipeline optimiert
sind — damit der Agent genaue Antworten finden und zitieren kann.
## Wie RAG-Chunking funktioniert (wichtig für die Dateistruktur)
- Jede Datei wird in Chunks von ~2000 Zeichen mit 20%
Überlappung an Satzgrenzen aufgeteilt
- Der Dateiname wird Teil der Embedding-Metadaten —
verwenden Sie beschreibende Namen
- Kürzere, fokussierte Dateien funktionieren besser als
eine große Datei
- Jeder Chunk sollte eigenständig verständlich sein
- Strukturierter Inhalt (Listen, Tabellen als Text, klare
Überschriften) wird besser aufgeteilt als Fließtext
## Deine Aufgabe
### Schritt 1: Gesamte Dokumentation analysieren
Lies jede Dokumentationsdatei des Projekts. Identifiziere
für jede Datei:
1. Das behandelte Thema
2. Wichtige Fakten, Einstellungen, Konfigurationen und Werte
3. Schritt-für-Schritt-Anleitungen
4. Funktionsbeschreibungen mit Details (Limits, Optionen, Formate)
5. Preise, Pläne und Kontingente (falls zutreffend)
6. Technische Details (APIs, Parameter, Integrationen)
### Schritt 2: Dateistruktur planen
Gruppiere verwandte Inhalte nach logischen Themen. Jede Datei
sollte EIN zusammenhängendes Thema abdecken. Zielgrößen:
- Ideal: 2.000–6.000 Zeichen pro Datei (1–3 Chunks)
- Maximum: 10.000 Zeichen (5 Chunks)
- Bei größeren Themen in Unterthemen aufteilen
Namenskonvention: {Themen-Name}.txt
- Beschreibende Namen mit Bindestrichen
- Keine Nummerierungspräfixe (Reihenfolge ist für RAG irrelevant)
- Der Name sollte auf den Inhalt hinweisen
Beispiele:
- Platform-Overview.txt
- Getting-Started.txt
- Pricing-Plans.txt
- API-Authentication.txt
- Webhook-Integration.txt
### Schritt 3: Dateien schreiben
Befolge für jede Datei diese Regeln:
Inhaltsregeln:
- Beginne mit einer klaren Themenüberschrift als Klartext
- Schreibe in Klartext — kein Markdown, kein HTML,
keine JSX-Komponenten
- Wandle Tabellen in lesbare Listen oder Schlüssel-Wert-Paare um
- Wandle Schritt-für-Schritt-Anleitungen in nummerierte Listen um
- Gib konkrete Werte an: Zahlen, Limits, Preise, Optionen,
Standardwerte, Formate, URLs
- Jeder Absatz sollte für sich verständlich sein
(eigenständige Chunks)
- Entferne Navigationselemente und Links ohne Informationswert
- Behalte die Originalsprache der Dokumentation bei
RAG-Optimierung:
- Wichtige Informationen voranstellen — Antwort vor Erklärung
- Einheitliche Terminologie in allen Dateien verwenden
- Schlüsselbegriffe natürlich wiederholen (verbessert die Suche)
- Bei Features mit Einstellungen: Name, Typ, Standardwert,
Optionen und Beschreibung auflisten
- Bei Integrationen: Anbieter, Auth-Methode, Setup-Schritte,
verfügbare Tools/Funktionen
Was ausgeschlossen werden soll:
- Screenshots und Bildreferenzen
- UI-Komponenten-Markup (Tabs, Accordions, Cards, Frames)
- "Siehe auch"-Links und Navigation
- Dekorativer Text und Marketing-Inhalte
- Doppelter Inhalt
### Schritt 4: Ausgabe erstellen
1. Erstelle ein temporäres Verzeichnis (z.B. temp-knowledge-base/)
2. Schreibe alle .txt-Dateien hinein
3. Liste alle Dateien mit Größen und Themenbeschreibungen auf
4. Gib eine Zusammenfassung: Gesamtzahl der Dateien und Größe
## Optional: Workflow-Agent-Seeder generieren
Wenn das Projekt Revol verwendet und du auch einen AI-Agenten
mit Workflow erstellen musst, generiere einen Laravel Database
Seeder, der:
1. Einen AiAgent erstellt mit:
- Passendem System-Prompt für Dokumentations-Support
- LLM: gpt-4o-mini, temperature: 0.3 (Genauigkeit)
- Personality: hohe Klarheit (8-9), hohe Formalität (6-7),
wenig Humor (2-3), wenig Emoji (1-2)
2. Einen Smart Router Workflow baut:
- Start-Node mit Keyword-Edges zu Experten-Nodes
- 3-6 Custom-"Experten"-Nodes, je eine Themengruppe
- Jeder Experte hat ein conversation_goal mit Domänenbeschreibung
- Jeder Experte hat search_documents + get_company_info Tools
- Ein Fallback-Edge zu einem General Assistant Node
- Alle Experten verbunden mit einem Formatter Node
- Voice-Nodes (STT/TTS) standardmäßig inaktiv
3. Keywords auf Edges sollten dem natürlichen Vokabular
der Nutzer entsprechen
## Eingabe
Meine Dokumentation befindet sich unter: [PFAD ODER URL]
Projektname: [NAME]
Projektbeschreibung: [KURZE BESCHREIBUNG]
Target company_id für Seeder: [ID oder Seeder überspringen]
```
Dieser Prompt funktioniert am besten mit umfassenden Dokumentationsportalen, Produktdokumentationen, API-Referenzen und Wissensdatenbanken. Die generierten .txt-Dateien können direkt in den Revol File Manager hochgeladen werden — einfach per Drag & Drop und dann auf **Train** klicken.
## Inhalte hinzufügen
### Dokumente
Laden Sie Dateien in unterstützten Formaten hoch:
* PDF
* DOCX
* TXT
### URLs
Geben Sie Webseiten-URLs an. Revol wird den Inhalt extrahieren und zur Wissensdatenbank hinzufügen.
### Text
Fügen Sie Inhalte direkt als Textblöcke hinzu.
## Wie RAG funktioniert
Sie laden ein Dokument hoch oder fügen Inhalte hinzu.
Der Inhalt wird in handhabbare Chunks aufgeteilt.
Jeder Chunk wird mithilfe des ausgewählten Embedding-Modells in ein Vektor-Embedding umgewandelt.
Embeddings werden in PostgreSQL mit der pgvector-Erweiterung gespeichert.
Wenn ein Benutzer eine Frage stellt, werden die ähnlichsten Chunks mittels Kosinusähnlichkeit abgerufen.
Abgerufene Chunks werden als Kontext in den LLM-Prompt injiziert.
## RAG-Einstellungen
Öffnen Sie die RAG-Einstellungen über das **Zahnrad-Symbol** (⚙) im Speicherpanel der Wissensdatenbank. Alle Einstellungen gelten pro Unternehmen und werden automatisch gespeichert.
### Embedding-Modell
Wählen Sie das Modell zur Umwandlung Ihres Textes in Vektor-Embeddings:
| Modell | Anbieter | Dimensionen | Preis | Ideal für |
| ---------------------- | --------- | ----------- | --------------- | ------------------------------------- |
| text-embedding-3-small | OpenAI | 1536 | \$0.02/1M Token | Allgemeine Nutzung, englischer Inhalt |
| text-embedding-3-large | OpenAI | 1536 | \$0.13/1M Token | Höhere Genauigkeit, englischer Inhalt |
| BGE-M3 | DeepInfra | 1024 | \$0.01/1M Token | Mehrsprachiger Inhalt (100+ Sprachen) |
Das Ändern des Embedding-Modells **löscht alle bestehenden Embeddings** des Unternehmens. Nach dem Wechsel müssen alle Agenten neu trainiert werden. Vor der Änderung erscheint ein Bestätigungsdialog.
### Chunk-Limit
Wie viele Textfragmente pro RAG-Suche zurückgegeben werden (1–20). Standard: **5**.
Höhere Werte liefern mehr Kontext für das LLM, erhöhen aber den Token-Verbrauch.
### Zeichenlimit
Maximale Zeichen pro Fragment beim Aufteilen von Dokumenten (500–10.000). Standard: **1.500**.
Kleinere Fragmente ermöglichen präziseres Retrieval. Größere bewahren mehr Kontext pro Ergebnis.
### Chunk-Überlappung
Überlappung zwischen aufeinanderfolgenden Fragmenten (0–40%). Standard: **15%**.
Überlappung stellt sicher, dass wichtiger Kontext an Fragment-Grenzen nicht verloren geht. Mehr Überlappung erzeugt mehr Chunks und verbraucht mehr Speicher.
### Ähnlichkeitsschwelle
Minimale Kosinus-Ähnlichkeit für ein Ergebnis (0,1–1,0). Standard: **0,35**.
Niedrigere Werte liefern mehr Ergebnisse (besserer Recall). Höhere Werte liefern nur hochrelevante Ergebnisse (bessere Präzision). Für mehrsprachige Inhalte verwenden Sie niedrigere Schwellen (0,3–0,4).
## Speicherlimits
| Plan | Wissensdokumente | Embedding-Tokens |
| ------------ | ---------------- | ---------------- |
| Free | 10 | 100.000 |
| Premium | 100 | 1.000.000 |
| Professional | 1.000 | 5.000.000 |
***
## Wissensdatenbank mit Claude Code generieren
Wenn Sie Projektdokumentation haben (Website-Seiten, Dokumentationsportal, README-Dateien, Wiki) und diese in eine strukturierte Wissensdatenbank für Ihren Revol AI-Agenten umwandeln möchten, können Sie **Claude Code** verwenden, um die Dokumentation zu analysieren und uploadfertige TXT-Dateien zu generieren.
```text theme={null}
# Anleitung: Wissensdatenbank-Dateien aus Dokumentation generieren
## Kontext
Ich verwende Revol — eine Plattform zur Erstellung von
AI-Vertriebsagenten mit RAG (Retrieval-Augmented Generation).
Mein Agent beantwortet Fragen mithilfe einer Wissensdatenbank:
Hochgeladene Dateien werden in Chunks aufgeteilt (max. 2000
Zeichen, 20% Überlappung), über OpenAI text-embedding-ada-002
(1536 Dimensionen) eingebettet, in PostgreSQL mit pgvector
gespeichert und zur Inferenzzeit per Kosinus-Ähnlichkeit
durchsucht.
Ich muss meine Projektdokumentation in eine Reihe von
.txt-Dateien umwandeln, die für diese RAG-Pipeline optimiert
sind — damit der Agent genaue Antworten finden und zitieren kann.
## Wie RAG-Chunking funktioniert (wichtig für die Dateistruktur)
- Jede Datei wird in Chunks von ~2000 Zeichen mit 20%
Überlappung an Satzgrenzen aufgeteilt
- Der Dateiname wird Teil der Embedding-Metadaten —
verwenden Sie beschreibende Namen
- Kürzere, fokussierte Dateien funktionieren besser als
eine große Datei
- Jeder Chunk sollte eigenständig verständlich sein
- Strukturierter Inhalt (Listen, Tabellen als Text, klare
Überschriften) wird besser aufgeteilt als Fließtext
## Deine Aufgabe
### Schritt 1: Gesamte Dokumentation analysieren
Lies jede Dokumentationsdatei des Projekts. Identifiziere
für jede Datei:
1. Das behandelte Thema
2. Wichtige Fakten, Einstellungen, Konfigurationen und Werte
3. Schritt-für-Schritt-Anleitungen
4. Funktionsbeschreibungen mit Details (Limits, Optionen, Formate)
5. Preise, Pläne und Kontingente (falls zutreffend)
6. Technische Details (APIs, Parameter, Integrationen)
### Schritt 2: Dateistruktur planen
Gruppiere verwandte Inhalte nach logischen Themen. Jede Datei
sollte EIN zusammenhängendes Thema abdecken. Zielgrößen:
- Ideal: 2.000–6.000 Zeichen pro Datei (1–3 Chunks)
- Maximum: 10.000 Zeichen (5 Chunks)
- Bei größeren Themen in Unterthemen aufteilen
Namenskonvention: {Themen-Name}.txt
- Beschreibende Namen mit Bindestrichen
- Keine Nummerierungspräfixe (Reihenfolge ist für RAG irrelevant)
- Der Name sollte auf den Inhalt hinweisen
Beispiele:
- Platform-Overview.txt
- Getting-Started.txt
- Pricing-Plans.txt
- API-Authentication.txt
- Webhook-Integration.txt
### Schritt 3: Dateien schreiben
Befolge für jede Datei diese Regeln:
Inhaltsregeln:
- Beginne mit einer klaren Themenüberschrift als Klartext
- Schreibe in Klartext — kein Markdown, kein HTML,
keine JSX-Komponenten
- Wandle Tabellen in lesbare Listen oder Schlüssel-Wert-Paare um
- Wandle Schritt-für-Schritt-Anleitungen in nummerierte Listen um
- Gib konkrete Werte an: Zahlen, Limits, Preise, Optionen,
Standardwerte, Formate, URLs
- Jeder Absatz sollte für sich verständlich sein
(eigenständige Chunks)
- Entferne Navigationselemente und Links ohne Informationswert
- Behalte die Originalsprache der Dokumentation bei
RAG-Optimierung:
- Wichtige Informationen voranstellen — Antwort vor Erklärung
- Einheitliche Terminologie in allen Dateien verwenden
- Schlüsselbegriffe natürlich wiederholen (verbessert die Suche)
- Bei Features mit Einstellungen: Name, Typ, Standardwert,
Optionen und Beschreibung auflisten
- Bei Integrationen: Anbieter, Auth-Methode, Setup-Schritte,
verfügbare Tools/Funktionen
Was ausgeschlossen werden soll:
- Screenshots und Bildreferenzen
- UI-Komponenten-Markup (Tabs, Accordions, Cards, Frames)
- "Siehe auch"-Links und Navigation
- Dekorativer Text und Marketing-Inhalte
- Doppelter Inhalt
### Schritt 4: Ausgabe erstellen
1. Erstelle ein temporäres Verzeichnis (z.B. temp-knowledge-base/)
2. Schreibe alle .txt-Dateien hinein
3. Liste alle Dateien mit Größen und Themenbeschreibungen auf
4. Gib eine Zusammenfassung: Gesamtzahl der Dateien und Größe
## Optional: Workflow-Agent-Seeder generieren
Wenn das Projekt Revol verwendet und du auch einen AI-Agenten
mit Workflow erstellen musst, generiere einen Laravel Database
Seeder, der:
1. Einen AiAgent erstellt mit:
- Passendem System-Prompt für Dokumentations-Support
- LLM: gpt-4o-mini, temperature: 0.3 (Genauigkeit)
- Personality: hohe Klarheit (8-9), hohe Formalität (6-7),
wenig Humor (2-3), wenig Emoji (1-2)
2. Einen Smart Router Workflow baut:
- Start-Node mit Keyword-Edges zu Experten-Nodes
- 3-6 Custom-"Experten"-Nodes, je eine Themengruppe
- Jeder Experte hat ein conversation_goal mit Domänenbeschreibung
- Jeder Experte hat search_documents + get_company_info Tools
- Ein Fallback-Edge zu einem General Assistant Node
- Alle Experten verbunden mit einem Formatter Node
- Voice-Nodes (STT/TTS) standardmäßig inaktiv
3. Keywords auf Edges sollten dem natürlichen Vokabular
der Nutzer entsprechen
## Eingabe
Meine Dokumentation befindet sich unter: [PFAD ODER URL]
Projektname: [NAME]
Projektbeschreibung: [KURZE BESCHREIBUNG]
Target company_id für Seeder: [ID oder Seeder überspringen]
```
Dieser Prompt funktioniert am besten mit umfassenden Dokumentationsportalen, Produktdokumentationen, API-Referenzen und Wissensdatenbanken. Die generierten .txt-Dateien können direkt in den Revol File Manager hochgeladen werden — einfach per Drag & Drop und dann auf **Train** klicken.